于2024年12月26日,我国人工智能初创企业DeepSeek正式推出其全新超大模型——DeepSeek-V3。该模型凭借开源代码和挑战业界领先AI供应商的创新技术而备受瞩目。
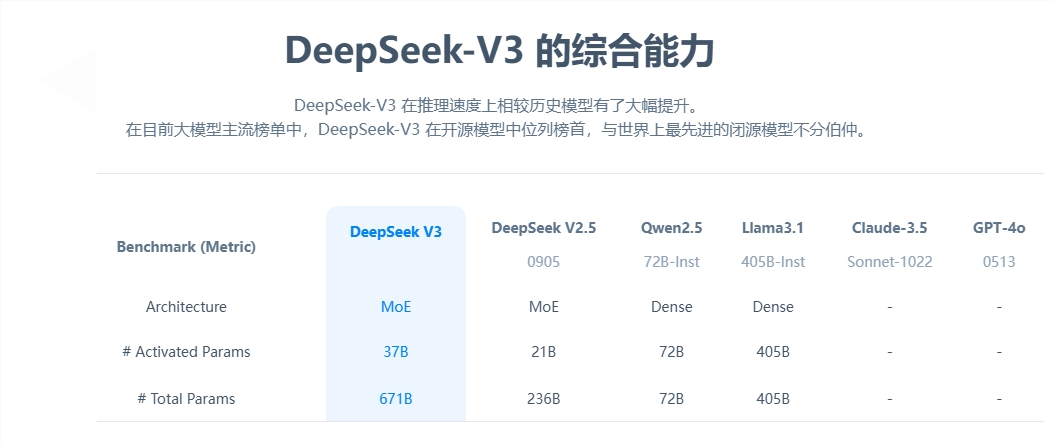
DeepSeek-V3拥有671B个参数,并运用专家混合架构(mixture-of-experts architecture)激活特定参数,确保对指定任务的精准高效处理。根据DeepSeek提供的基准测试,这款新模型已超越了包括Meta的Llama3.1-405B在内的顶级开源模型,其性能与Anthropic和OpenAI的封闭模型不相上下。

DeepSeek-V3的推出标志着开源AI与封闭源AI之间的差距进一步缩小。DeepSeek,作为最初由我国量化对冲基金High-Flyer Capital Management孵化出的分支,期待这些进步能够为通用人工智能(AGI)的发展奠定基础,届时模型将能够执行人类能够执行的任何智力任务。
DeepSeek-V3的关键特性包括:
与先前的DeepSeek-V2相同,新模型基于多头潜在注意力(MLA)和DeepSeekMoE的基本架构,确保了高效训练和推理。
公司还推出了两项创新:辅助无损失负载平衡策略和多令牌预测(MTP),后者允许模型同时预测多个未来令牌,提升了训练效率,并使模型运行速度提升三倍,每秒生成60个令牌。
在预训练阶段,DeepSeek-V3对14.8T高质量和多样化的令牌进行了训练,并进行了两阶段的上下文长度扩展,最终通过监督式微调(SFT)和强化学习(RL)的后训练,使模型与人类偏好保持一致,进一步挖掘其潜力。
在训练阶段,DeepSeek采用了多种硬件和算法优化,包括FP8混合精度训练框架和DualPipe算法进行流水线并行,大幅降低了训练成本。DeepSeek-V3的整个训练过程声称在2788K H800GPU小时或约557万美元内完成,远低于通常用于预训练大型语言模型的数亿美元。
DeepSeek-V3已成为市场上最强大的开源模型。公司进行的各项基准测试显示,它在多数基准测试中超越了封闭源GPT-4o,除了在以英语为焦点的SimpleQA和FRAMES测试中,OpenAI模型分别以38.2和80.5的得分领先(DeepSeek-V3得分分别为24.9和73.3)。DeepSeek-V3在中文和数学基准测试中的表现尤为出色,在Math-500测试中得分为90.2,其次是Qwen的80分。
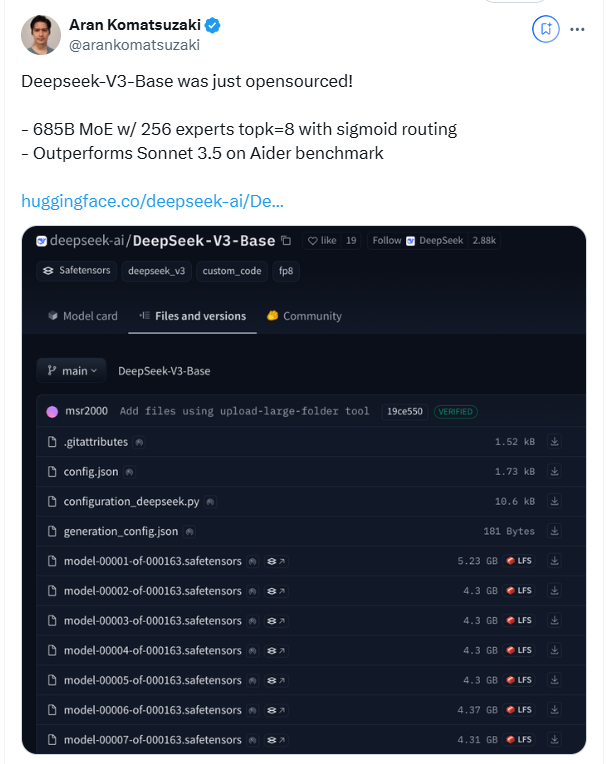
目前,DeepSeek-V3的代码可在GitHub上以MIT许可证获取,模型则根据公司的模型许可证提供。企业可通过DeepSeek Chat(类似于ChatGPT的平台)测试新模型,并访问API进行商业使用。DeepSeek将提供与DeepSeek-V2相同价格的API,直至2月8日。之后,将按每百万输入令牌0.27美元(缓存命中每百万令牌0.07美元)和每百万输出令牌1.10美元的费用收费。
划重点:
🌟 DeepSeek-V3发布,性能超越Llama和Qwen。
🔧 采用671B参数和专家混合架构,提高效率。
🚀 创新包括无损失负载平衡策略和多令牌预测,提升速度。
💼 训练成本大幅降低,推动开源AI发展。


暂无评论