幻方量化于12月26日晚推出了全新的大模型DeepSeek-V3,这一技术创新令人瞩目。该模型采用了MoE(混合专家)架构,不仅在性能上与顶尖闭源模型相媲美,其低成本与高效能的特性也引起了业界的广泛关注。
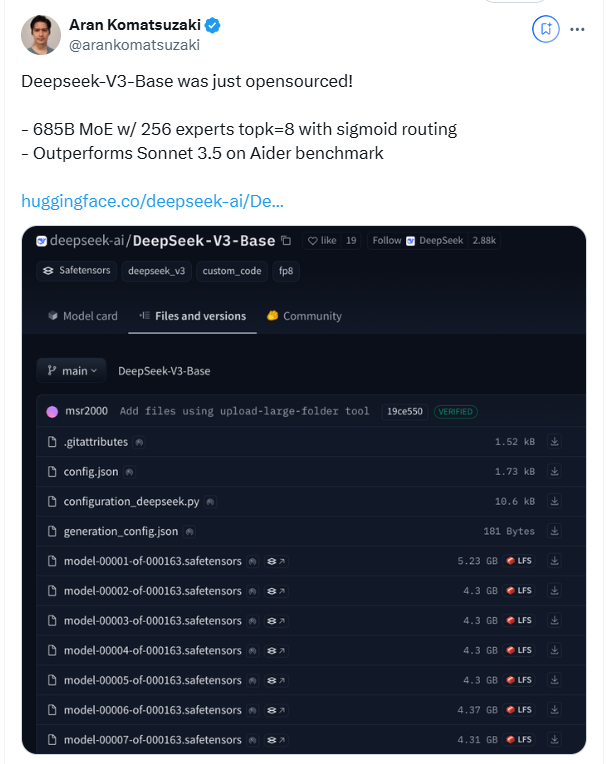
从核心参数来看,DeepSeek-V3拥有6710亿参数,其中激活参数为370亿,在14.8万亿token的数据规模上完成了预训练。与上一代产品相比,新模型的生成速度提升了3倍,每秒可处理60个token,大幅提高了实际应用效率。

在性能测试中,DeepSeek-V3展现了其卓越的性能。它不仅超越了Qwen2.5-72B和Llama-3.1-405B等知名开源模型,在多项测试中,其表现也与GPT-4和Claude-3.5-Sonnet不相上下。特别是在数学能力测试中,该模型以优异的成绩超越了所有现有的开源和闭源模型。
DeepSeek-V3的低成本优势同样引人注目。根据开源论文的披露,以每GPU小时2美元的成本计算,模型的全部训练成本仅为557.6万美元。这一突破性的成果得益于算法、框架和硬件的协同优化。OpenAI联合创始人Karpathy对其给予了高度评价,指出DeepSeek-V3仅用280万GPU小时就达到了超越Llama3的性能,计算效率提高了约11倍。
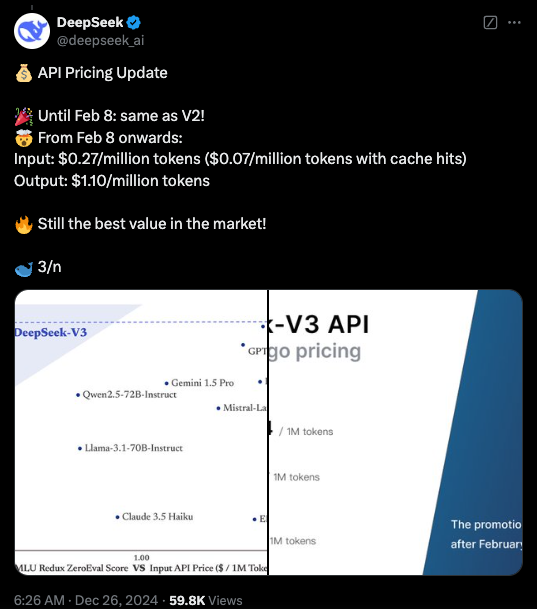
在商业化方面,尽管DeepSeek-V3的API服务定价相比上一代有所上调,但依然保持了较高的性价比。新版本的价格为每百万输入tokens 0.5-2元,输出tokens 8元,总成本约为10元人民币。相比之下,GPT-4的同等服务价格约为140元人民币,价格差异明显。
作为一款全面开源的大模型,DeepSeek-V3的发布不仅标志着中国AI技术的进步,还为开发者和企业提供了一个高性能、低成本的AI解决方案。

暂无评论