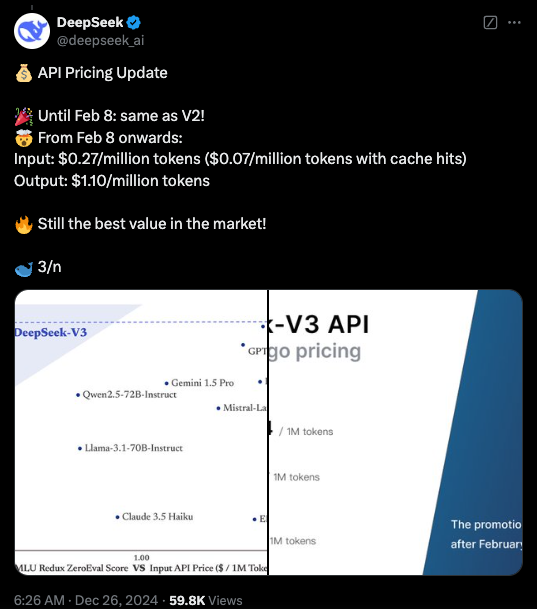
中国人工智能企业DeepSeek最近推出了具有划时代意义的开源大型语言模型DeepSeek V3。该模型拥有6710亿参数,其规模超越了Meta的Llama3.1,并在多项基准测试中超过了包括GPT-4在内的主流封闭源模型。
DeepSeek V3的显著优势在于其卓越的性能和高效的开发流程。在编程平台Codeforces的比赛中,该模型表现出色;在测试代码集成能力的Aider Polyglot测试中,它也领先于其他竞争对手。模型训练使用了14.8万亿token的庞大数据集,参数规模是Llama3.1的1.6倍。
 (图片来源:AI合成)")
值得注意的是,DeepSeek仅用两个月时间、耗资550万美元便完成了模型训练,这个成本远低于同类产品的开发费用。
DeepSeek的背后支持者是中国量化对冲基金High-Flyer Capital Management。该基金投资建设了一个由10,000个Nvidia A100GPU组成的、价值约1.38亿美元的服务器集群。High-Flyer创始人梁文峰表示,开源AI将最终打破当前封闭模型的垄断优势。
DeepSeek V3采用宽松的许可证发布,允许开发者下载、修改并用于各类应用,包括商业用途。尽管运行完整版本需要强大的硬件支持,但这一开源模型的发布标志着AI领域开放创新的重要进展。




暂无评论