
DeepSeek-VL2视觉语言模型发布:高效处理高分辨率图像与文本数据
DeepSeek-AI推出DeepSeek-VL2系列视觉语言模型,采用动态切片、多头潜在注意机制,适应不同需求,提升高分辨率图像处理效率,光学字符识别准确率达92.3%,视觉定位精准度提升15%,计算需求降低30%,表现卓越。
DeepSeek-AI推出DeepSeek-VL2系列视觉语言模型,采用动态切片、多头潜在注意机制,适应不同需求,提升高分辨率图像处理效率,光学字符识别准确率达92.3%,视觉定位精准度提升15%,计算需求降低30%,表现卓越。
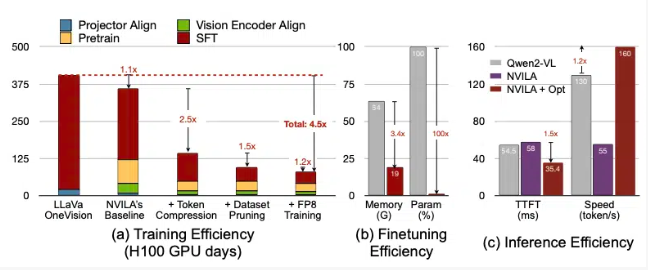
NVIDIA推出NVILA视觉语言模型,训练成本降低4.5倍,内存需求减少3.4倍,性能优于同类模型,确保高分辨率输入信息完整,将发布代码促进研究复现。
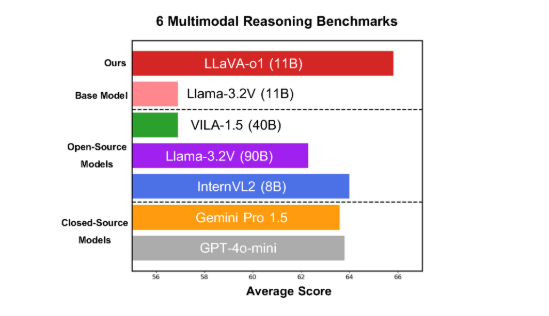
北京大学发布多模态开源模型LLaVA-o1,具备自发、系统推理能力,超越同类模型。在多模态基准测试中表现优异,推理过程分四阶段,提升准确性。模型即将全面开源,助力多模态AI发展。
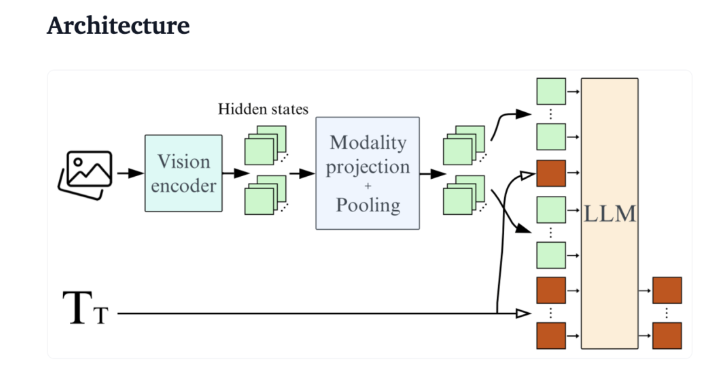
SmolVLM 是 Hugging Face 推出的一款针对设备端推理的轻量化视觉语言模型,具备2B参数,能够在低资源环境下高效运行。与同期模型相比,SmolVLM 的令牌生成速度提升了7.5到16倍,同时优化了架构,大大降低了对硬件的要求。它在处理视觉语言任务时表现出色,测试中对50帧 YouTube 视频的适应能力也展现了良好的性能。SmolVLM 的推出,使得强大的机器学习能力更加易于接触,填补了当前AI工具的一项重要空白。