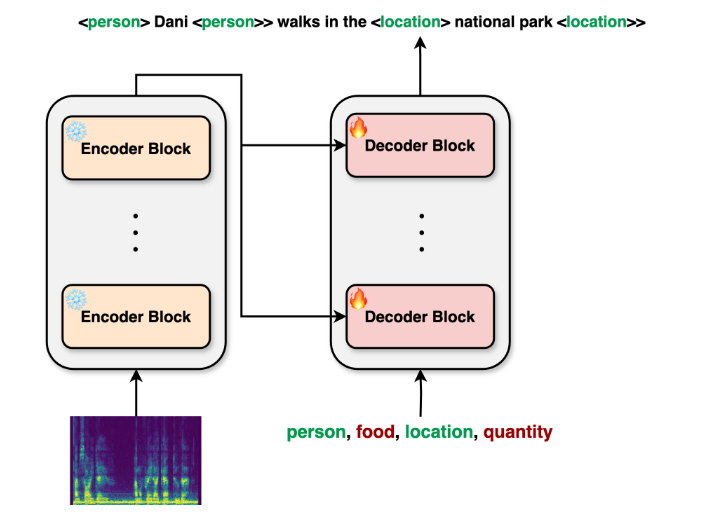
Teuken-7B 是一款具备 70 亿参数的语言模型,刚刚在 Hugging Face 上正式发布,支持欧盟的所有 24 种官方语言。这款模型由欧盟的 OpenGPT-X 研究项目团队开发,并作为开源项目提供给用户使用。与大多数侧重英语的 AI 语言模型不同,Teuken-7B 从零开始构建,大约有一半的训练数据来自于非英语的欧洲语言。
")
图源备注:图片由AI生成,图片授权服务商Midjourney
开发团队指出,Teuken-7B 在所有训练的语言中都展现了优异的性能,尤其是在处理非英语语言时,其可靠性让人印象深刻。为了评估语言模型在欧洲语言的表现,项目团队还特意创建了一个新的欧洲 LLM 排行榜,超越了以往主要基于英语的标准测试方法。
这一发布为欧洲在推广多语言人工智能模型方面带来了重大突破,同时也为开发者提供了一个强大而多样化的工具,以助力跨语言的应用和研究。




暂无评论