阿里巴巴Qwen团队最近发表了题为《数学推理中过程奖励模型的开发经验教训》的研究论文,并推出了Qwen2.5-Math-PRM系列中的两个新模型,分别拥有7B和72B的参数。这两个模型在数学推理上突破了传统PRM框架的限制,凭借创新技术显著提升了推理模型的准确性和泛化能力。
数学推理一直是大型语言模型(LLM)面临的重要挑战,特别是在中间推理步骤中,错误很容易影响最终输出的准确性。这对那些对精确度要求极高的领域,如教育和科学计算,尤为成问题。传统的评估方法,如Best-of-N(BoN)策略,无法充分捕捉推理过程的复杂性,因此,过程奖励模型(PRM)应运而生,旨在通过评估中间步骤的正确性来提供更详细的监督。
然而,构建高效的PRM面临着数据注释和评估方法的挑战,这也是现有模型无法完全解决的难题。因此,需要一种更符合稳健、过程驱动推理的模型。
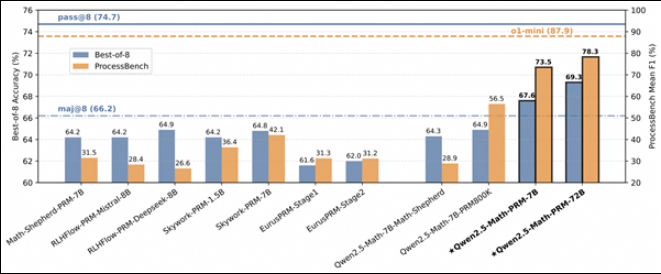
Qwen团队的创新方法结合了蒙特卡洛(MC)估计和“LLM作为判断”的机制。这种混合方法提高了分步注释的质量,使得PRM能够更有效地识别并减轻数学推理中的错误。通过这一技术,Qwen2.5-Math-PRM系列模型在PROCESSBENCH等基准测试中表现出色,特别是在找出中间推理错误的能力上。
共识过滤:仅当MC估计和LLM作为判断者都确认步骤正确性时,才保留数据,这显著减少了训练中的噪音。硬标记:经过双重机制验证的确定性标签增强了模型区分有效和无效推理步骤的能力。高效数据利用:将MC估计与LLM作为判断相结合的共识过滤策略,确保了高质量的数据,并保持了可扩展性。
这些创新帮助Qwen2.5-Math-PRM模型不仅提高了准确性,还增强了其在自动辅导和复杂问题解决等应用中的表现。
Qwen2.5-Math-PRM系列在多个评估指标上表现出色。例如,Qwen2.5-Math-PRM-72B模型的F1得分高达78.3%,超过了众多开源替代品。特别是在需要逐步识别错误的任务中,它的表现优于GPT-4-0806等专有模型。
共识过滤机制有效降低了数据噪声约60%,显著提高了训练数据的质量。此外,Qwen2.5-Math-PRM强调分步评估,而非传统的基于结果的BoN策略,这解决了早期模型通常过于依赖最终答案而忽视推理准确性的问题。
Qwen2.5-Math-PRM系列的推出标志着数学推理领域的重大进步。通过解决PRM开发中的难题,如数据注释的噪声和过程到结果的偏差,Qwen团队提供了一个提高推理准确性和可靠性的实用框架。随着该技术的不断发展,预计未来PRM模型将在更广泛的AI应用中发挥重要作用,提升机器推理系统的可靠性和有效性。




暂无评论