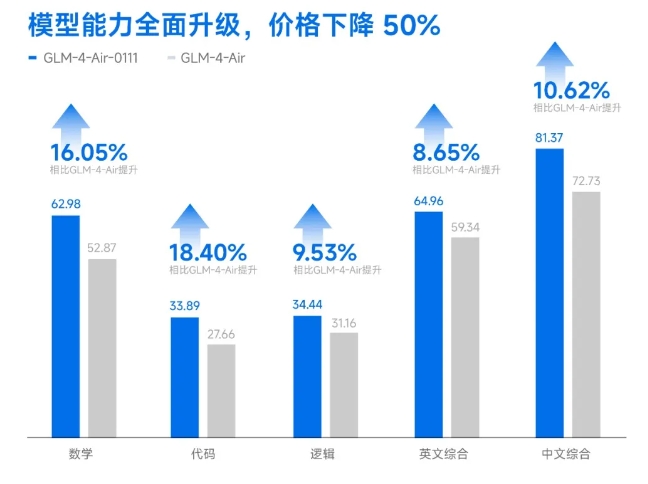
近日,阿里云通义团队宣布推出全新的数学推理奖励模型Qwen2.5-Math-PRM。该模型提供72B和7B两种规模,性能上明显超越同类开源模型,尤其在识别推理错误方面表现优异。
令人惊喜的是,Qwen2.5-Math-PRM的7B版本在性能上超越了业界知名模型GPT-4o,这标志着阿里云在推理模型研发领域迈出了关键步伐。为全面评估模型在数学推理方面的表现,通义团队还发布了首个步骤级评估标准——ProcessBench。该标准包含3400个数学问题测试案例,包括国际奥林匹克数学竞赛的难题,每个案例都由专家详细标注推理过程,确保评估的科学性和全面性。

在ProcessBench上的评估结果显示,不论是72B还是7B版本的Qwen2.5-Math-PRM,都表现出色。尤其是7B版本,不仅超越了同尺寸的开源模型,在某些方面甚至超越了闭源的GPT-4o-0806。这证明了过程奖励模型(PRM)在提升推理可靠性方面的巨大潜力,并为未来推理过程监督技术的发展提供了新思路。

阿里云通义团队的这项创新工作,不仅推动了人工智能推理技术的进步,也为行业内的开发者提供了宝贵的借鉴。通过开源,通义团队期望与更多研究者分享经验,共同推动行业技术发展。



暂无评论