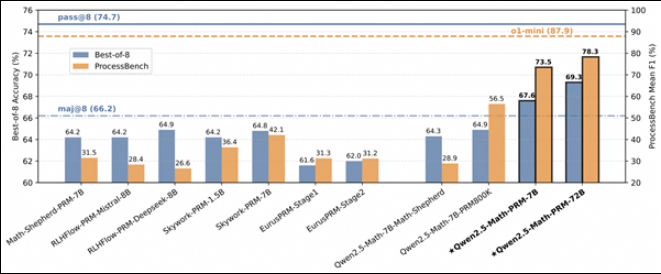
阿里云发布Qwen2.5-Math-PRM,数学推理模型性能突破
阿里云发布全新数学推理模型Qwen2.5-Math-PRM,性能优于同类开源模型,开源评估标准ProcessBench推动推理技术发展。
阿里云发布全新数学推理模型Qwen2.5-Math-PRM,性能优于同类开源模型,开源评估标准ProcessBench推动推理技术发展。


阿里巴巴Qwen团队推出“PROCESSBENCH”新基准测试,专注评估语言模型在数学推理中的错误识别能力,包含3400个专家标注测试案例。研究发现现有模型在高难度问题上表现不佳,PROCESSBENCH为AI推理过程理解提供重要框架。
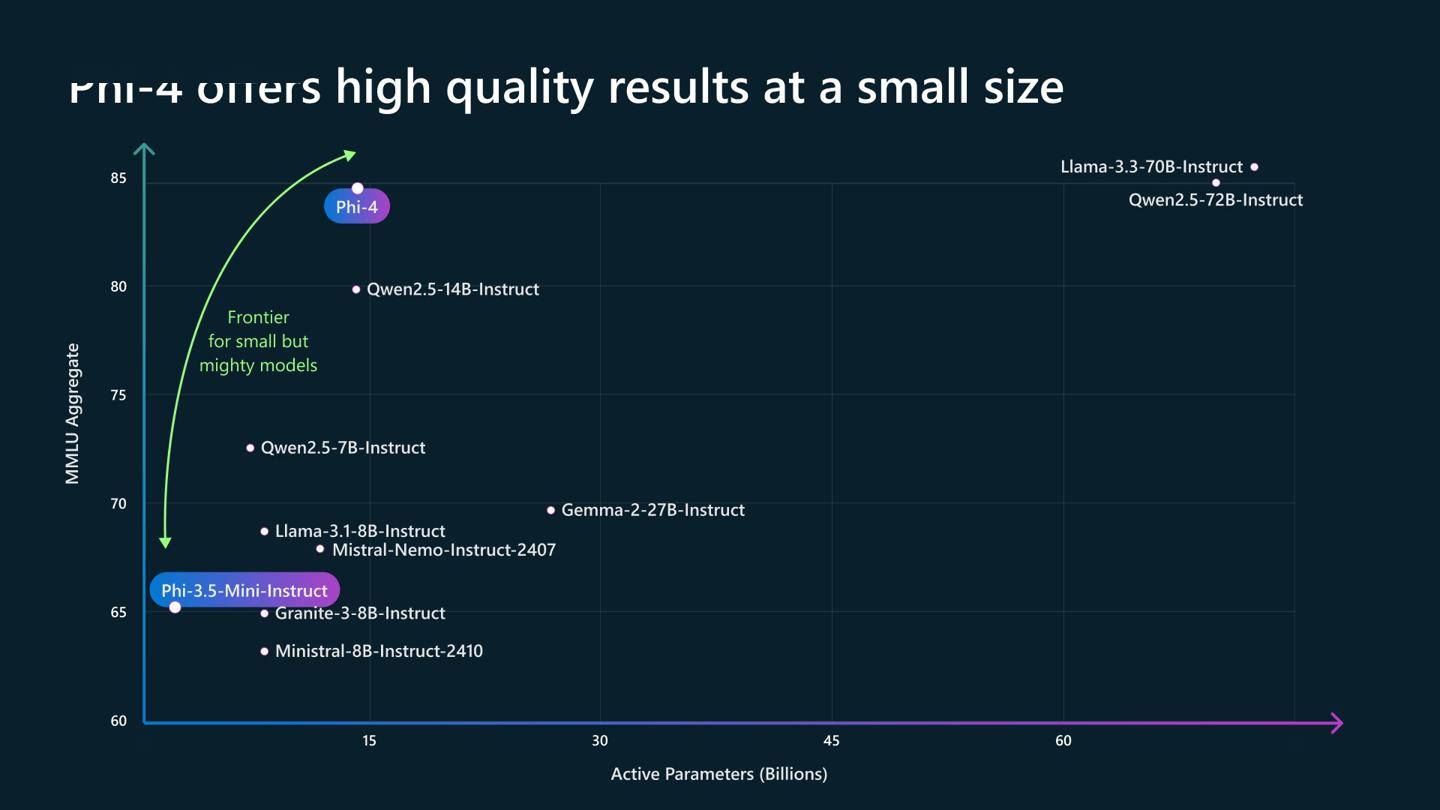
微软推出Phi-4小型语言模型,14B参数,数学推理领域领先,采用高质量数据集训练,保障数据隐私安全,已在Azure AI Foundry开放使用。

Kimi智能助手推出新一代数学推理模型k0-math,在多项数学基准测试中成绩优异,超过OpenAI o1系列模型。采用强化学习和思维链推理技术,提升解题能力,计划持续迭代以应对更高难度题目。
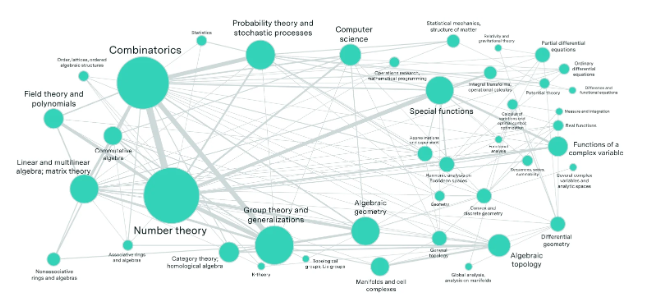
FrontierMath是一个新推出的基准测试,旨在挑战人工智能的数学推理能力,号称"数学奥林匹克"。由Epoch AI与60多位数学界顶级专家共同开发,测试包括超高难度的数学问题,如数论和代数几何。令人震惊的是,主流AI模型在该测试中表现不佳,仅解决2%的题目。这一结果凸显了人类与人工智能在解决数学问题上的反直觉差异,同时反映出AI在复杂任务中的局限性。FrontierMath也为AI研究者提供了新的挑战与发展方向。