最近,阿里巴巴Qwen团队研究人员推出了一项名为“PROCESSBENCH”的新基准测试,目的是衡量语言模型在数学推理过程中识别错误步骤的能力。尽管语言模型在复杂推理任务上取得了显著进步,但研究者们发现,在处理一些难题时,模型仍面临挑战。因此,开发一种有效的监督手段显得尤为重要。

目前,针对语言模型的评估基准存在一些缺陷。一方面,一些问题对高级模型来说过于简单,另一方面,现有的评估方法往往只提供正确与否的二元评价,缺乏详细的错误分析。这表明,我们需要一个更全面的评估体系,以深入了解复杂语言模型的推理机制。
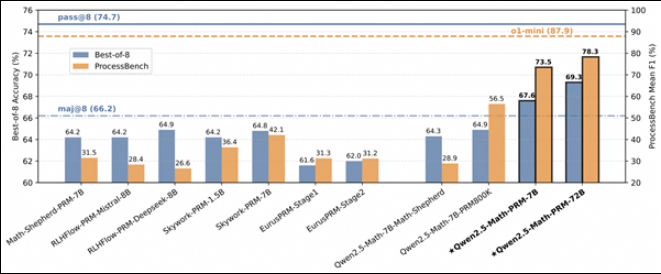
为了弥补这一不足,研究人员开发了“PROCESSBENCH”基准,专注于识别数学推理中的错误步骤。该基准的设计理念包括问题的难度、解决方案的多样性和全面的评估。它针对竞赛和奥林匹克级别的数学问题,使用多个开源语言模型生成不同的解题方案。PROCESSBENCH包含了3400个由多位专家精心标注的测试案例,确保了数据质量和评估的准确性。

在开发过程中,研究团队从四个著名的数据集(GSM8K、MATH、OlympiadBench 和 Omni-MATH)中收集数学问题,覆盖了从小学到竞赛级别的广泛难度。他们利用开源模型生成了多达12种不同的解决方案,以增加解决方案的多样性。同时,为了统一解题步骤的格式,团队采用了重格式化方法,确保了逻辑上的逐步推理完整性。
研究结果显示,现有的过程奖励模型在处理高难度问题时表现不佳,尤其在简单问题集上,提示驱动的评判模型表现更为出色。研究揭示了现有模型在评估数学推理时的局限性,尤其是在模型通过错误中间步骤得出正确答案时,难以进行准确判断。
作为评估语言模型识别数学推理错误能力的先行者,“PROCESSBENCH”为未来的研究提供了重要参考,推动了AI在推理过程中的理解和改进。
论文链接: https://github.com/QwenLM/ProcessBench?tab=readme-ov-file
代码链接: https://github.com/QwenLM/ProcessBench?tab=readme-ov-file
重点内容:
🌟 新基准“PROCESSBENCH”旨在评估语言模型在数学推理中识别错误的能力。
📊 “PROCESSBENCH”包含3400个测试案例,覆盖多种难度的数学问题,并由专家精心标注。
🔍 研究发现,现有过程奖励模型在高难度问题上表现不佳,需改进错误识别策略。




暂无评论