近期,国产大模型DeepSeek V3在AI竞技领域的卓越表现引起了广泛关注。作为唯一跻身前十的开源模型,它不仅超越了o1-mini,还在编程、数学等多个领域超过了Claude3.5Sonnet。为了验证其实际能力,各方进行了多轮实测对比。

在基础理解能力测试中,两个模型表现各异。面对中文脑筋急转弯“小明的妈妈有三个孩子”,DeepSeek V3表现出色,不仅答对问题,还进行了自我验证。然而,在英文双关语“April Fool's Day”的测试中,它未能理解其中的语言巧思,而Claude3.5Sonnet则轻松应对。

逻辑推理测试中,两个模型都遭遇了“弱智吧”经典逻辑陷阱,出现了误判。但在“反转诅咒”类问题上,双方都展现出了出色的推理能力,成功识别出汤姆·克鲁斯与其母亲的关系。

在考研数学题的较量中,DeepSeek V3展现出了更强的数学能力。它不仅能够详细解析曲面积分和高斯定理的应用,还成功得出正确答案。相比之下,Claude3.5Sonnet虽然思路清晰,但最终计算结果有误。

编程能力对比中,DeepSeek V3在网站创建测试中击败了对手,这一结果进一步印证了其在竞技场排名中的出色表现。
值得一提的是,随着满血版o1的加入,AI竞技场格局再次发生变化。o1以绝对优势登顶榜首,除创意写作外,几乎包揽了所有单项第一。

这一系列测试表明,中国自研大模型正在迅速追赶国际领先水平。DeepSeek V3的表现证明,在特定领域它已经具备了与顶级模型抗衡的实力,为国产AI技术发展注入了新的信心。


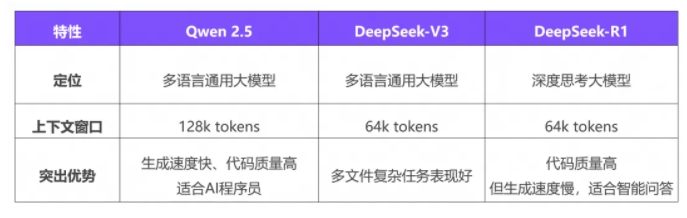
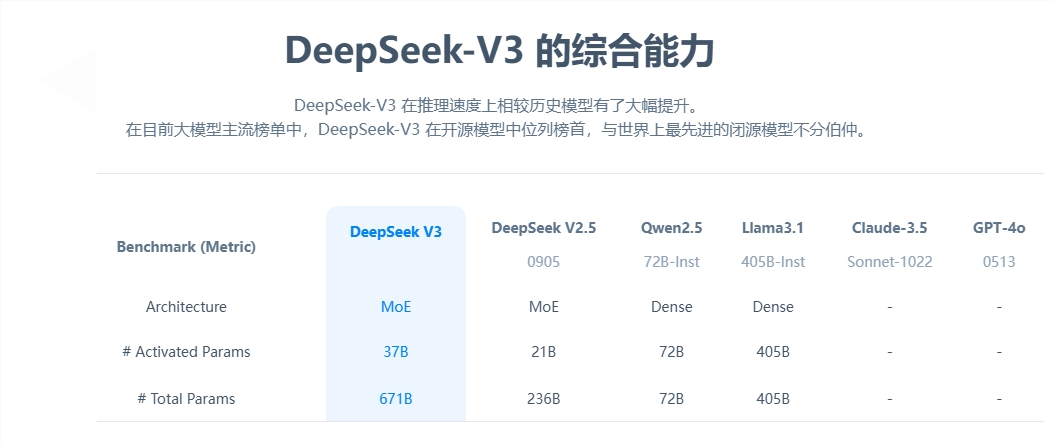
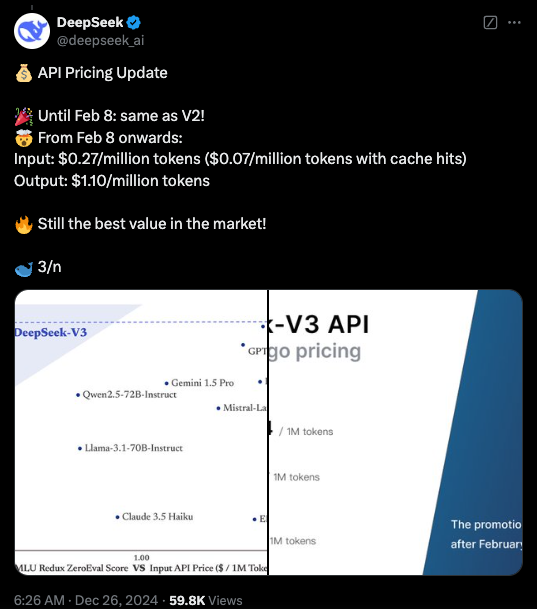
暂无评论