DeepSeek-V3,一款功能强大的混合专家(Mixture-of-Experts, MoE)语言模型,总参数量高达6710亿,每个token激活37亿参数。该模型采用了创新的多头潜在注意力(Multi-head Latent Attention, MLA)架构和经过验证的DeepSeekMoE架构。CogAgent实施了无辅助损失的负载均衡策略,并提出多token预测训练目标,显著提升了模型性能。它在1480万高质量token上进行了预训练,并通过监督微调和强化学习阶段,充分挖掘了其潜力。
在多个标准基准测试中,DeepSeek-V3表现出色,特别是在数学和代码任务上,成为当前最强大的开源基础模型。其训练成本较低,全程训练的稳定性也受到高度认可。
昨日,DeepSeek全新系列模型DeepSeek-V3首个版本上线并同步开源。用户可通过访问官网chat.deepseek.com与最新版V3模型进行对话。API服务已同步更新,接口配置无需改动。当前版本的DeepSeek-V3暂不支持多模态输入输出。
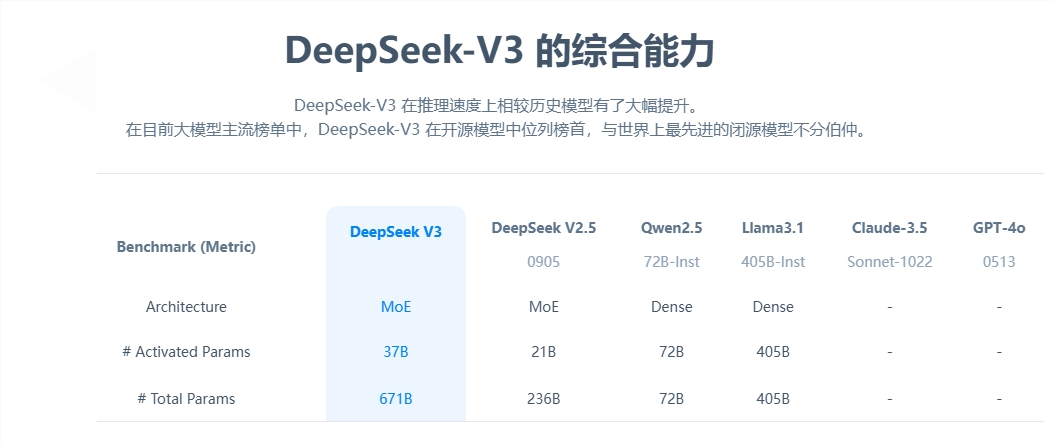
DeepSeek-V3为自研MoE模型,拥有671B参数,激活37B,在14.8T token上进行了预训练。论文链接:[DeepSeek_V3.pdf](https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf)
DeepSeek-V3在多项评测成绩上超越了Qwen2.5-72B和Llama-3.1-405B等开源模型,性能上与闭源模型GPT-4o和Claude-3.5-Sonnet不相上下。
- **百科知识**:DeepSeek-V3在知识类任务(MMLU, MMLU-Pro, GPQA, SimpleQA)上的水平相比前代DeepSeek-V2.5显著提升,接近当前表现最好的模型Claude-3.5-Sonnet-1022。
- **长文本**:在长文本测评中,DROP、FRAMES和LongBench v2上,DeepSeek-V3平均表现超越其他模型。
- **代码**:DeepSeek-V3在算法类代码场景(Codeforces)远远领先于市面上已有的全部非o1类模型;在工程类代码场景(SWE-Bench Verified)逼近Claude-3.5-Sonnet-1022。
- **数学**:在美国数学竞赛(AIME 2024, MATH)和全国高中数学联赛(CNMO 2024)上,DeepSeek-V3大幅超过了所有开源闭源模型。
- **中文能力**:DeepSeek-V3与Qwen2.5-72B在教育类测评C-Eval和代词消歧等评测集上表现相近,但在事实知识C-SimpleQA上更为领先。
通过算法和工程上的创新,DeepSeek-V3的生成吐字速度从20 TPS大幅提高至60 TPS,相比V2.5模型实现了3倍提升,为用户带来更加迅速流畅的使用体验。
随着DeepSeek-V3的更新上线,模型API服务定价也将调整为每百万输入tokens 0.5元(缓存命中)/ 2元(缓存未命中),每百万输出tokens 8元。为庆祝全新模型上线,我们决定设置长达45天的优惠价格体验期:即日起至2025年2月8日,DeepSeek-V3的API服务价格仍为每百万输入tokens 0.1元(缓存命中)/ 1元(缓存未命中),每百万输出tokens 2元,已注册的老用户和在此期间内注册的新用户均可享受以上优惠价格。
DeepSeek-V3采用FP8训练,并开源了原生FP8权重。SGLang、LMDeploy、TensorRT-LLM和MindIE等社区已支持V3模型的原生FP8推理和BF16推理。为方便社区适配和拓展应用场景,我们提供了从FP8到BF16的转换脚本。模型权重下载和更多本地部署信息请参考:[DeepSeek_V3-Base](https://huggingface.co/deepseek-ai/DeepSeek-V3-Base)
相关文章:
- 达摩院“寻光”视频创作平台全面评测
- Mymind:AI信息收集工具,智能书签管理,打造个人专属的智能收藏空间
- 全面解析Notepads功能:实现Cursor编辑器与聊天之间无缝上下文共享
- LongBench v2:评估长文本+o1?
- kimi推出视觉版o1,用视觉思考并解决问题






暂无评论