近期,备受关注的 Qwen2.5-VL 系列模型新增成员——Qwen2.5-VL-32B-Instruct 正式开源。这款拥有320亿参数的多模态视觉语言模型,在继承 Qwen2.5-VL 系列优势的同时,通过强化学习等技术优化,显著提升了性能,尤其在复杂推理和用户体验方面表现优异。
(adsbygoogle=window.adsbygoogle||[]).push({});
据悉,今年1月底,Qwen 团队发布了 Qwen2.5-VL 系列模型,并迅速获得社区广泛关注和积极反馈。为满足社区期待,并持续推动多模态模型技术发展,团队在 Qwen2.5-VL 系列基础上,历时数月精心打磨,最终推出这款全新的 Qwen2.5-VL-32B-Instruct 模型,并采用 Apache 2.0 协议开源,旨在惠及更广泛的开发者和研究者。
性能飞跃,多项指标超越前代及同类模型
官方数据显示,Qwen2.5-VL-32B-Instruct 模型相较于 Qwen2.5-VL 系列,在多个关键性能指标上实现显著提升。
首先,在用户主观偏好方面,新模型通过调整输出风格,使回复内容更详实、格式更规范,更符合人类阅读习惯和偏好。这意味着用户在使用过程中,将获得更流畅、更自然的交互体验。
其次,在数学推理能力方面,Qwen2.5-VL-32B-Instruct 模型在复杂数学问题求解的准确性上取得显著进步。这表明该模型在逻辑推理和计算能力上得到有效增强,能更好地应对需要深入思考和精确计算的任务。
此外,在图像细粒度理解与推理方面,Qwen2.5-VL-32B-Instruct 模型展现出更强的实力。无论是在图像解析的精度、内容识别的广度,还是视觉逻辑推导的深度上,新模型都表现出了更高的水准,能更准确、更细致地分析图像信息。
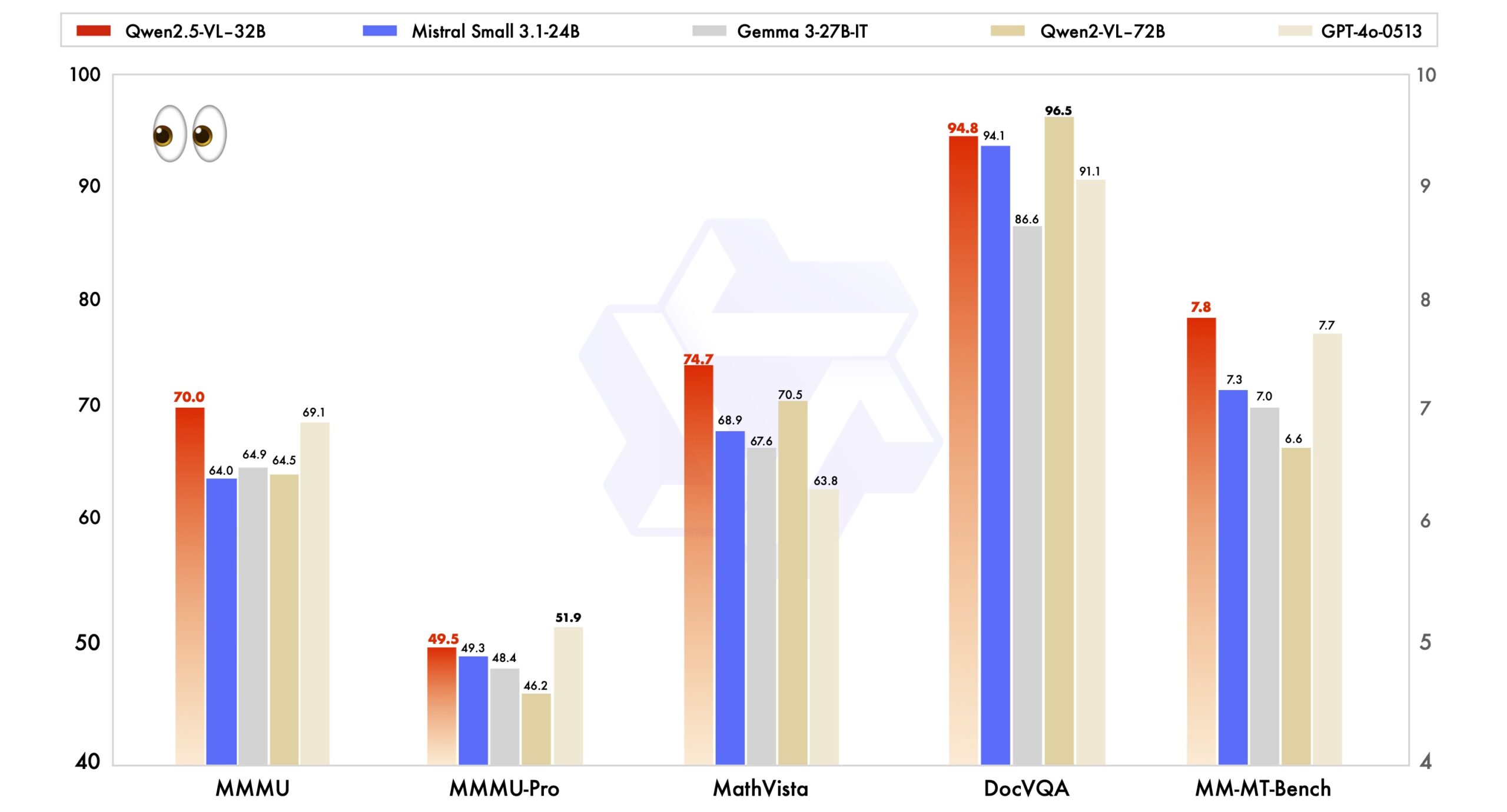
为直观展现 Qwen2.5-VL-32B-Instruct 模型的性能优势,官方还将其与业内领先的同规模模型,包括 Mistral-Small-3.1-24B 和 Gemma-3-27B-IT 进行了对比测试。结果显示,Qwen2.5-VL-32B-Instruct 模型在多项多模态任务中表现出明显优势,部分指标甚至超越了更大规模的 Qwen2-VL-72B-Instruct 模型。尤其是在 MMMU、MMMU-Pro 和 MathVista 等强调复杂多步骤推理的任务中,Qwen2.5-VL-32B-Instruct 模型的突出表现令人印象深刻。而在注重用户主观体验的 MM-MT-Bench 基准测试中,该模型也相较于前代 Qwen2-VL-72B-Instruct 取得了显著的进步。

值得一提的是,Qwen2.5-VL-32B-Instruct 模型不仅在视觉能力上表现出色,在纯文本能力方面也达到了同规模模型的最优水平。

技术亮点:动态分辨率、高效视觉编码器
Qwen2.5-VL 系列模型在技术架构上也进行了一系列创新升级。
在视频理解方面,模型采用了动态分辨率和帧率训练技术,通过引入动态 FPS 采样,使模型能理解不同采样率的视频内容。同时,在时间维度上更新了 mRoPE (多相对位置编码),并结合 IDs 和绝对时间对齐,使模型能学习时间序列和速度信息,从而具备捕捉视频关键时刻的能力。

在视觉编码器方面,Qwen2.5-VL 系列模型采用了精简高效的 Vision Encoder。通过在 ViT (Vision Transformer) 中策略性地引入窗口注意力机制,并结合 SwiGLU 和 RMSNorm 等优化手段,使得 ViT 架构与 Qwen2.5 LLM 的结构更加一致,从而有效提升了模型训练和推理的速度。
开源普惠,助力多模态应用创新
Qwen2.5-VL-32B-Instruct 模型的开源发布,将为多模态视觉语言领域注入新的活力。开发者和研究人员可基于该模型进行更深入的研究和更广泛的应用开发,例如图像和视频内容理解、智能 Agent、跨模态内容生成等。
目前,Qwen2.5-VL-32B-Instruct 模型已在 Hugging Face Transformers 和 ModelScope 等平台上线,并提供详细的代码示例和使用指南,方便用户快速上手体验。Qwen 团队也表示,将持续关注社区反馈,不断优化和完善 Qwen2.5-VL 系列模型,为推动多模态技术的发展贡献力量。
对于希望体验 Qwen2.5-VL-32B-Instruct 模型的用户,可通过以下方式快速开始:
环境配置
建议用户从源码构建 transformers 库,以确保兼容性:
pip install git+https://github.com/huggingface/transformers accelerate快速上手代码示例 (使用 🤗 Transformers):
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# 加载模型
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-32B-Instruct", torch_dtype="auto", device_map="auto"
)
# 加载 processor
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-32B-Instruct")
# 构建 messages
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# 预处理
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# 模型推理
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
Qwen2.5-VL-32B-Instruct 模型的发布,为多模态视觉语言模型领域带来了新的突破,其在性能、技术和开源方面的优势,有望加速多模态技术的普及和应用,值得业界持续关注。





暂无评论