最近,阿里云百炼平台宣布开放 QwQ-32B 大语言模型的 API 接口,并免费提供每日 100 万 tokens 的额度。这一举措降低了用户体验前沿 AI 技术的门槛,尤其对那些想体验 QwQ-32B 模型但受限于本地硬件的用户来说,通过云端 API 接口是更佳选择。
对于不了解 QwQ-32B 的朋友,建议阅读:小模型,大能量:QwQ-32B 以 1/20 参数硬刚满血 DeepSeek-R1
(adsbygoogle=window.adsbygoogle||[]).push({});
API 接口优势:突破硬件限制,轻松获取强大算力
此前,我们发布了《本地部署 QwQ-32B 大模型:个人电脑轻松上手指南》。想要体验大型语言模型如 QwQ-32B,通常需要高性能计算设备。高昂的硬件配置,如 24GB 显存等,让许多用户难以触及 AI 体验。阿里云百炼平台通过 API 接口解决了这一问题。
使用 API 接口调用 QwQ 模型,用户可享受以下优势:
- 无门槛硬件配置:无需本地高性能硬件,降低使用门槛。即便是轻薄笔记本电脑或智能手机,也能流畅运行云端强大的模型算力。建议用户使用配备 24G 显存或更高规格的显卡,以获得更流畅的本地模型运行体验。
- 系统兼容性:API 接口与操作系统无关,具有跨平台特性。无论用户使用 Windows、macOS 还是 Linux 系统,都能方便接入。
- 更强的 Plus 版本:用户可以体验到性能更优的 QwQ Plus 增强版模型,其性能超越了本地部署的 QwQ-32B 满血版。Plus 版本,即通义千问 QwQ 推理模型增强版,基于 Qwen2.5 模型并经过强化学习训练。相较于基础版本,Plus 版本在模型推理能力上显著提升,在数学代码等核心指标以及部分通用指标评测中,均达到了 DeepSeek-R1 满血版模型的水平。
- 高速响应:API 接口实现了快速响应,速率可达 40-50 tokens/秒。这意味着用户可以获得近乎实时的交互体验,大幅提升使用效率。
值得一提的是,除了阿里云百炼,硅基流动平台也提供了 QwQ-32B 模型的 API 接口。若用户对硅基流动平台感兴趣,可以参考之前的文章。本文将主要介绍阿里云百炼平台提供的 API 接口使用方法。
阿里云百炼 API 接入指南:简单三步,快速上手
阿里云百炼平台为 QwQ 系列模型 API 用户提供每日 100 万 tokens 的免费额度。对于大多数用户而言,这一额度足以满足日常体验和测试需求。用户只需完成简单的注册和配置,即可开始使用。
以下是在客户端配置阿里云百炼 QwQ Plus API 的简要步骤:
1. 获取 API Key 和模型名称
首先,访问阿里云百炼平台并完成注册或登录。
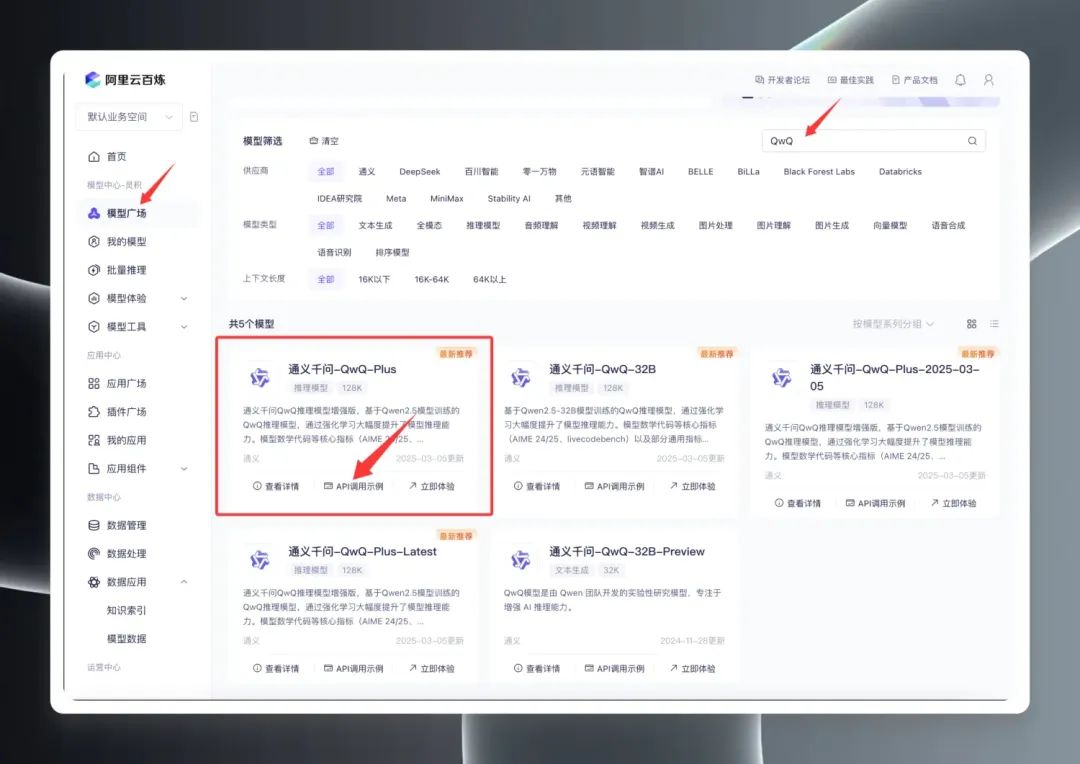
登录后,在模型广场搜索 “QwQ”,即可看到 QwQ 系列模型。实际上,模型广场展示了三个主要版本:QwQ32B (正式版)、QwQ32B-Preview (预览版) 以及 QwQ Plus (增强版,亦称商用版)。
选择 “QwQ Plus (增强版)”,点击 “API 调用示例”,在新的页面中找到模型名称 qwq-plus。

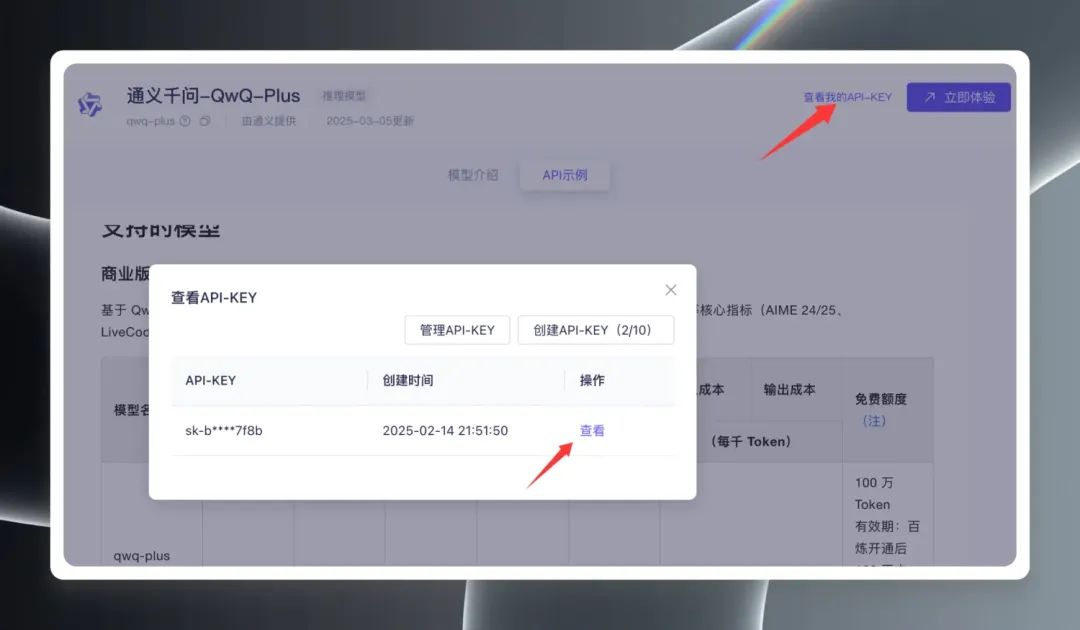
接着,点击页面右上角的 “查看我的 API Key”,首次使用需要创建 API Key,如果已创建则直接查看并复制 API Key。
2. 客户端配置
本文以 Chatwise 客户端为例进行演示。打开 Chatwise 软件,点击用户头像,进入 “设置” 界面。
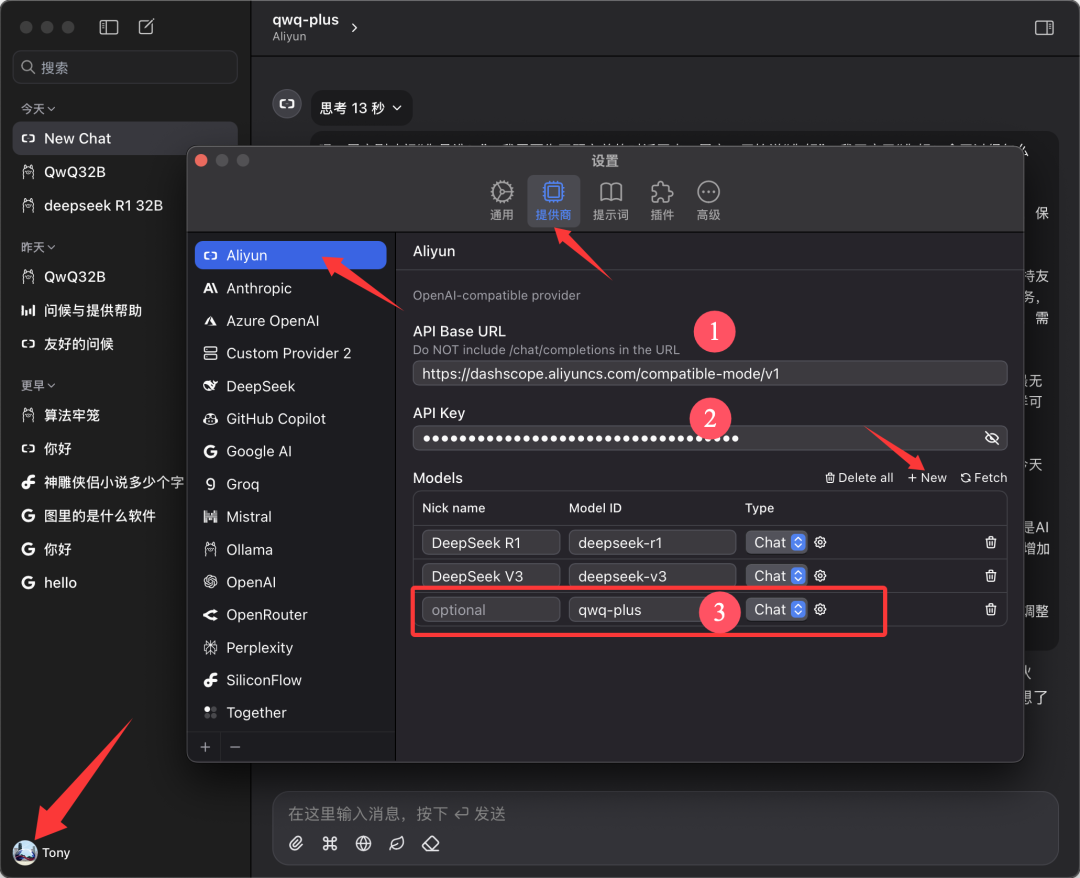
在供应商列表中找到 “Aliyun”,如果未找到,点击底部的 “➕” 添加。
按照下图所示,进行配置:
- API Base URL:
https://bailian.aliyuncs.com(通用) - API Key: 粘贴上一步复制的 API Key
- 模型: 添加模型名称
qwq-plus(必须为该名称)
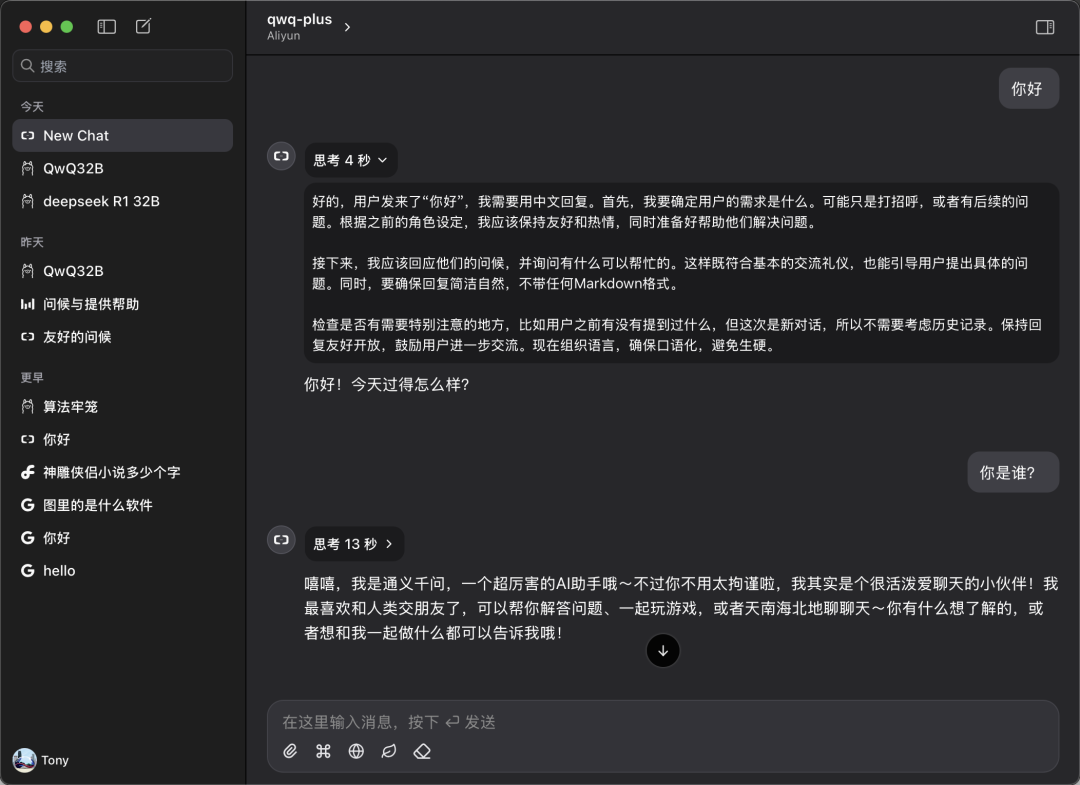
3. 开始体验
返回 Chatwise 主界面,在模型选择下拉菜单中选中 “qwq-plus” 模型,即可开始对话体验。
性能实测:性能优异,甚至超越本地部署
为了验证 QwQ Plus API 的实际性能,我们进行了简单的对比测试。
速度测试:
实测表明,QwQ Plus API 接口速度表现出色,速率稳定在 40-50 tokens/秒。相比之下,同在阿里云百炼平台上线的 DeepSeek R1 模型 API,速率则明显偏慢,仅为 10+ tokens/秒。
兼容性测试:
用户也可以在 CherryStudio 等客户端上配置并使用 QwQ Plus API。但在测试 CherryStudio 过程中,观察到一个潜在问题:当模型进行长时间复杂推理时,CherryStudio 可能会占用较多系统资源,在部分配置的设备上可能出现软件重启现象。然而,在相同硬件环境下使用 Chatwise 客户端,则未出现类似问题。这可能与不同客户端的开发框架存在差异有关。
能力对比:
我们沿用之前的帽子颜色逻辑推理题,对比本地 QwQ32 模型和 QwQ Plus API 的表现。
问题描述:
有 5 个人排成一排,每人帽子颜色为红色或蓝色。他们可以看到前面的人的帽子,但看不到自己的。主持人宣布:“至少有一顶红帽子。”从最后一人开始,每人依次说“是”或“否”(表示是否知道自己帽子的颜色)。如果第 5 人说“否”,第 4 人说“是”,求所有可能的帽子颜色分布。
本地 QwQ32 模型表现:

本地 QwQ32 模型在经过两次尝试后,最终成功解答,第二次耗时 196 秒。
QwQ Plus API 表现:
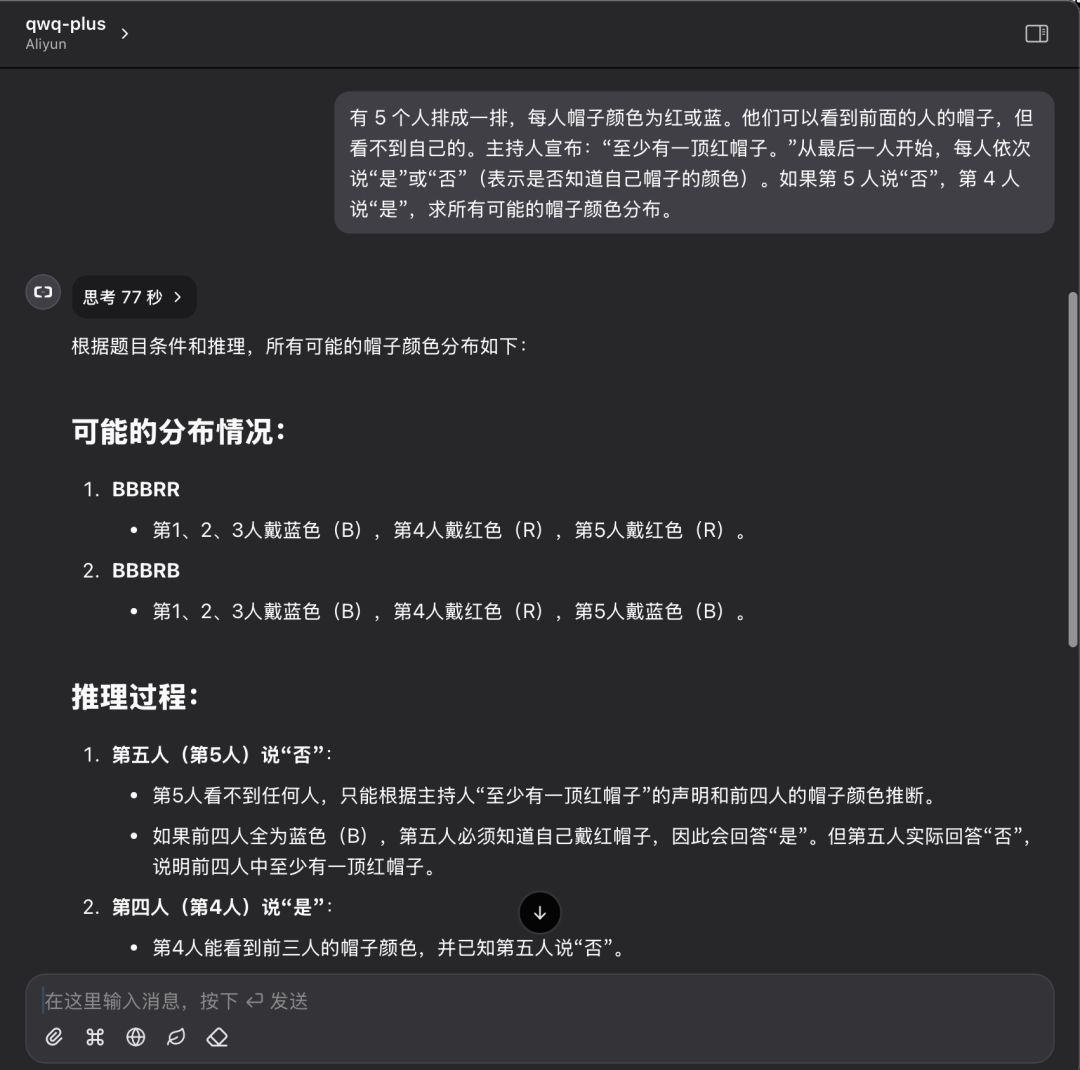
QwQ Plus API 在相同问题上的表现:一次性给出正确答案,耗时 77 秒。
测试结果分析:
虽然单个案例不足以全面评估模型能力,但本次测试结果能够直观地反映出本地部署模型与云端 API 方案的差异。在解决逻辑推理问题时,两种方案均能给出正确答案,但 QwQ Plus API 在效率和推理过程的清晰度上更胜一筹,推理耗时更短,token 消耗也更少。
拥抱云端 AI,人人可享
阿里云百炼平台免费开放 QwQ-32B API 接口,并提供慷慨的免费 tokens 额度,无疑是推动大语言模型技术普及的重要一步。借助 API 接口,用户无需投入高昂的硬件成本,即可在云端轻松体验高性能 AI 模型带来的强大能力。无论你是开发者、研究人员还是 AI 爱好者,现在都可以充分利用阿里云百炼提供的免费资源,开启你的 AI 探索之旅。






暂无评论