
2025年2月26日,SuperCLUE发布项目级代码生成(SuperCLUE-Project)测评基准首期榜单。
(adsbygoogle = window.adsbygoogle || []).push({});
测评方案见:项目级代码生成测评基准发布。本次测评基于大模型“裁判团”的合作,全方位评价了国内外12个大模型在项目级代码生成任务上的能力,任务涵盖包括了游戏开发、工具和管理系统等5大类应用场景。以下为详细测评报告。
项目级代码测评摘要
摘要1:o3-mini-high与Claude-3.7-Sonnet-Reasoning处于领跑地位
本次测评中,OpenAI发布的o3-mini-high取得综合成绩82.08分,Anthropic公司最新发布的推理模型Claude-3.7-Sonnet-Reasoning的综合成绩达到81.63分,二者携手领跑榜单。
摘要2:DeepSeek-R1领跑国内模型,跻身业界第一梯队
从测评结果看,DeepSeek-R1与o3-mini-high、Claude-3.5-Sonnet/3.7-Sonnet-Reasoning、Gemini-2.0-pro等业界前沿模型得分差距极小,甚至在部分应用场景下取得了一定的领先地位。
摘要3:各有所长。R1擅长游戏开发,o3/阶跃Step R擅长多媒体编辑,多家擅长网络应用
本次参评的12个模型,均呈现出在不同应用场景下的能力差异,如DeepSeek-R1在“游戏开发”领域表现突出,Claude-3.5-Sonnet、豆包1.5pro和通义千问Max更加擅长“网络应用”设计,阶跃星辰Step R-mini在“多媒体编辑”工具开发中有独特优势等。
摘要4:不同模型在方法选择、界面风格上差异明显
对比模型答案发现,面对相同用户需求,不同模型选择的编程语言、调用的库/模块大相径庭,对界面美观度的重视程度也有显著差异,一定程度上反映了模型的能力、偏好、理念等差异。
榜单概览 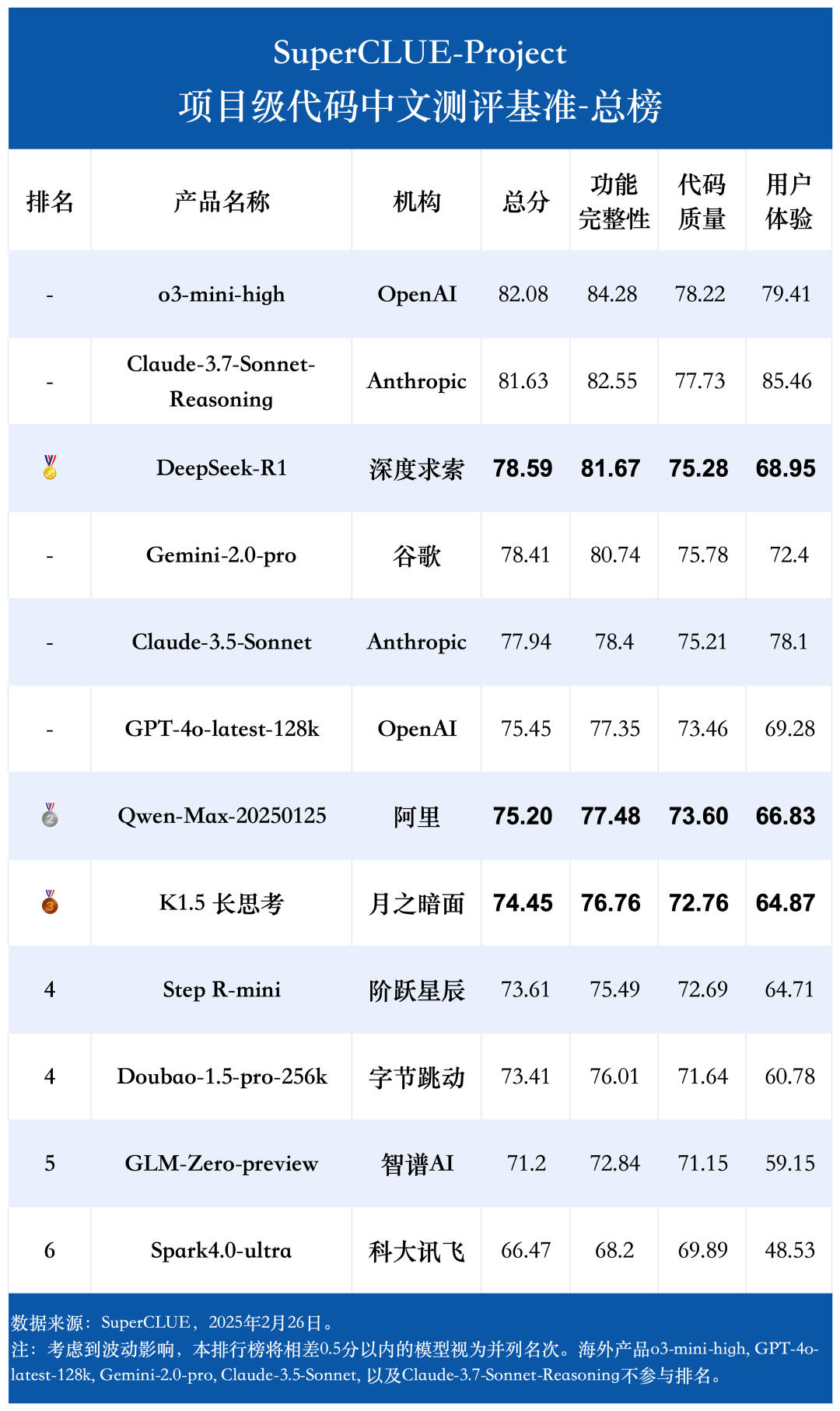
SuperCLUE-Project测评体系
SuperCLUE-Project是中文原生项目级代码测评基准,旨在考察大模型将用户的项目级需求转变成代码实现的能力。 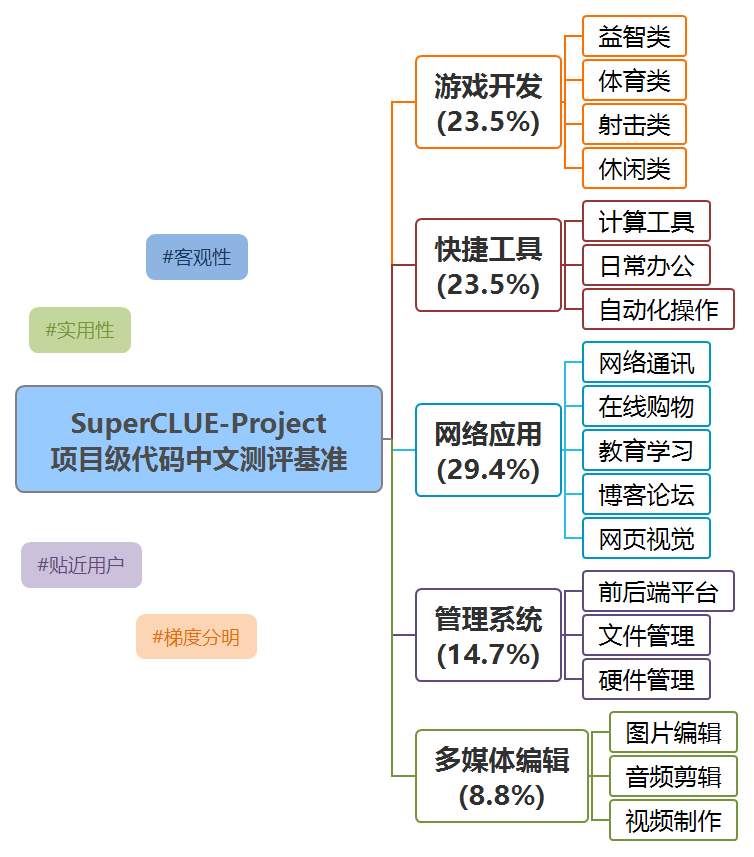
SuperCLUE-Project围绕非程序员用户群体的实际需求,涵盖5个一级维度、18个二级维度,以中文自然语言构建题目集。鉴于非程序员群体特点,我们在题目设计中仅强调功能层面的需求描述,而将效率、安全、可读性等指标作为大模型选手的独立能力,置于测评环节加以评估。
此外,基准还设置了简单--中等--复杂三级难度,针对同一题目集进行整体扩展,为模型的项目级代码实现能力提供更深的洞见。
测评方法
参考SuperCLUE细粒度评估方式,遵循以下流程进行测评:
1) 测评集构建
1.关注大模型辅助的低代码/零代码开发领域动态,收集整理非程序员群体代码项目需求
2.编写简单难度的项目级代码测评集
3.控制格式和字数范围,将测评集扩展至中等/复杂难度
4.测试和人工校验
2) 评分过程
1.编写评价规则prompt--->
2.小范围测试,人工检验裁判模型与人类专家的评价一致性--->
3.根据一致性反馈,反复调优评价规则--->
4.将待测模型回答和评价规则完整传入两个裁判模型,分别接收完整评价--->
5.计算两个裁判模型在各维度的评分均值作为最终结果
3) 人类一致性分析
对测评集进行分层抽样,通过计算组内相关系数检验裁判模型与人类专家的评价一致性,并报告该表现。
相较于以往的基准,SuperCLUE-Project在实施测评的过程中首次引入国内、国外两个模型(Gemini-2.0-flash和Qwen-Max)同时作为裁判员,通过“裁判团”的合作,进一步减少了大模型的偏差 (bias) 和偏好 (preference) 问题。
此外,为验证裁判模型的可靠性,SuperCLUE-Project首次引入组内相关系数 (Intra-class Correlation Coefficient, ICC),通过计算人类专家、Qwen-Max和Gemini-2.0-flash三者评分的双向混合效应 (ICC(3,k)) 指数,验证了裁判模型与人类评价具有强一致性。相比过去的百分比可靠性,该方法有效克服了随机误差带来的波动影响。
(*注:组内相关系数(ICC)是衡量和评价观察者间信度(inter-observer reliability)和复测信度(test-retest reliability)的信度系数指标之一,最早由Bartko于1966年用于测量和评价信度的大小。ICC等于个体的变异度除以总的变异度。在本实验中,由于我们仅需考虑选定的裁判模型和人类专家的评价一致性,无需扩展到其他评分者,故选择双向混合效应指数作为一致性指标。)
评估标准
- 功能完整性 (60%):确保代码





暂无评论