近期,微软在Phi-4系列的基础上推出了两款新型号:Phi-4多模态和Phi-4迷你。这两款新模型的发布,无疑将为各种人工智能应用带来更强大的处理能力。
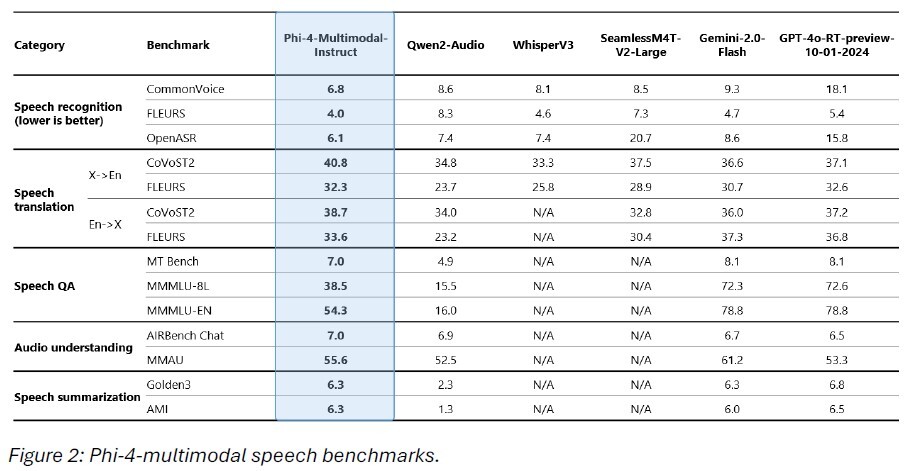
Phi-4多模态模型是微软首次推出的集成了语音、视觉和文本处理的统一架构模型,拥有5600万参数。在多项基准测试中,Phi-4多模态模型的表现超越了市场上的众多竞争对手,包括谷歌的Gemini2.0系列。在自动语音识别(ASR)和语音翻译(ST)任务中,Phi-4多模态模型表现出色,成功击败了WhisperV3和SeamlessM4T-v2-Large等专业语音模型,词错误率仅为6.14%,在Hugging Face OpenASR排行榜上名列前茅。

在视觉处理方面,Phi-4多模态模型同样表现出色。其在数学和科学推理方面的能力令人印象深刻,能够有效理解文档、图表,并执行光学字符识别(OCR)。与Gemini-2-Flash-lite-preview和Claude-3.5-Sonnet等流行模型相比,Phi-4多模态模型的表现不相上下,甚至在某些方面更胜一筹。
Phi-4迷你模型专注于文本处理任务,参数量为3800万。在文本推理、数学计算、编程和指令遵循等方面,Phi-4迷你模型表现出色,超越了多款流行的大型语言模型。为确保新模型的安全性和可靠性,微软邀请了内部与外部的安全专家进行全面测试,并按照微软人工智能红队(AIRT)的标准进行优化。
这两款新模型均可通过ONNX Runtime部署到不同设备上,适用于多种低成本和低延迟的应用场景。它们已在Azure AI Foundry、Hugging Face和NVIDIA API目录中上线,供开发者使用。Phi-4系列的新模型标志着微软在高效AI技术上的重大突破,为未来的人工智能应用开辟了新的道路。



暂无评论