Kimi k1.5技术报告速读
1. 强大的多模态推理能力:
Kimi k1.5 模型在多个基准测试和模态上实现了最先进的推理性能,涵盖数学、代码、文本和视觉推理等任务。
(adsbygoogle=window.adsbygoogle||[]).push({});
它不仅处理纯文本,还能理解图像与文本的组合,实现真正的多模态推理。
long-CoT 和 short-CoT 版本均展现了强大的性能。
在AIME、MATH 500、Codeforces等数据集上均达到了领先水平。
在视觉基准测试如MathVista上也有较强的表现。
2. 长上下文 RL 训练的突破:
通过将上下文窗口扩展至128k,模型性能持续提升,验证了上下文长度是强化学习扩展的关键维度。
- 采用部分 rollout 技术,显著提高长上下文 RL 训练效率,使得训练更长、更复杂的推理过程成为可能。
- 证明了长上下文对复杂问题解决能力至关重要。
3. 有效的 long2short 方法:
- 提出有效的 long2short 方法,利用长上下文模型知识改进短上下文模型性能,并提高 Token 效率。
- 通过模型合并、最短拒绝采样、DPO 等技术实现短模型性能提升,且比直接训练短模型更高效。
证明了通过迁移 long-CoT 模型的思维先验知识可以提高短模型性能。
4. 优化的 RL 训练框架:
提出改进的策略优化方法,无需依赖复杂技术即可实现强大性能。
探索多种采样策略、长度惩罚和数据配方优化,提升 RL 训练效率和效果。
通过消融研究验证所提出方法和训练技巧的有效性。
5. 详细的训练过程和系统设计:
- 公开 Kimi k1.5 的详细训练配方,包括预训练、微调和强化学习阶段。
- 介绍混合部署策略,优化训练和推理过程中的资源利用率。
- 详细介绍数据管道和质量控制机制,确保训练数据质量。
- 开发安全的代码沙箱,用于执行和评估生成的代码。
6. 模型规模与上下文长度的探索:
研究了模型规模和上下文长度对性能的影响,发现规模较大的模型性能更好,但使用更长上下文的小型模型也能接近甚至媲美大模型的性能,证明了 RL 训练对模型性能的增强。
摘要
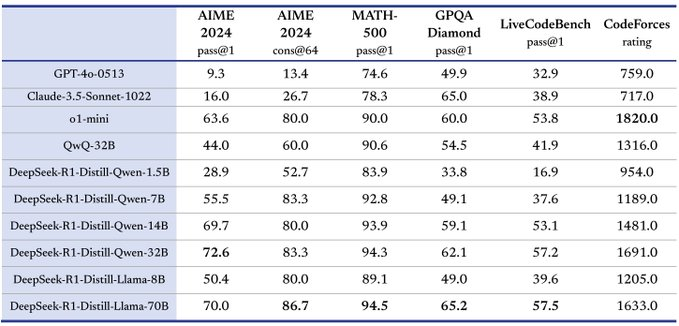
使用下一个 Token 预测进行语言模型预训练已被证明可以有效地扩展计算量,但受限于可用的训练数据量。扩展强化学习 (RL) 为人工智能的持续改进开辟了一个新的维度,有望通过学习探索奖励来扩展大型语言模型 (LLM) 的训练数据。然而,先前发表的工作并未产生具有竞争力的结果。鉴于此,我们报告了 Kimi k1.5 的训练实践,Kimi k1.5 是我们最新的使用 RL 训练的多模态 LLM,包括其 RL 训练技术、多模态数据配方和基础设施优化。长上下文扩展和改进的策略优化方法是我们方法的关键要素,它建立了一个简单有效的 RL 框架,而无需依赖更复杂的技术,例如蒙特卡罗树搜索、价值函数和过程奖励模型。值得注意的是,我们的系统在多个基准测试和模态上实现了最先进的推理性能——例如,在 AIME 上达到 77.5,在 MATH 500 上达到 96.2,在 Codeforces 上达到第 94 个百分位数,在 MathVista 上达到 74.9,与 OpenAI 的 01 相匹配。此外,我们提出了有效的 long2short 方法,该方法使用长 Co





暂无评论