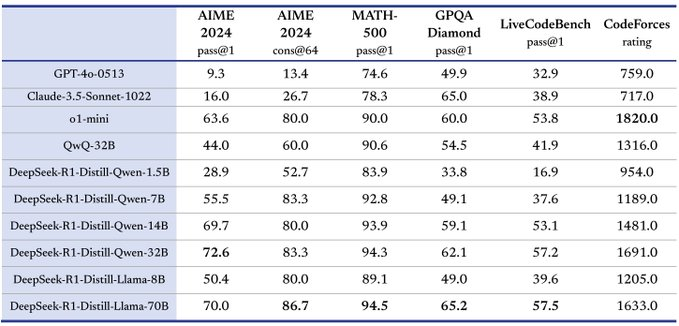
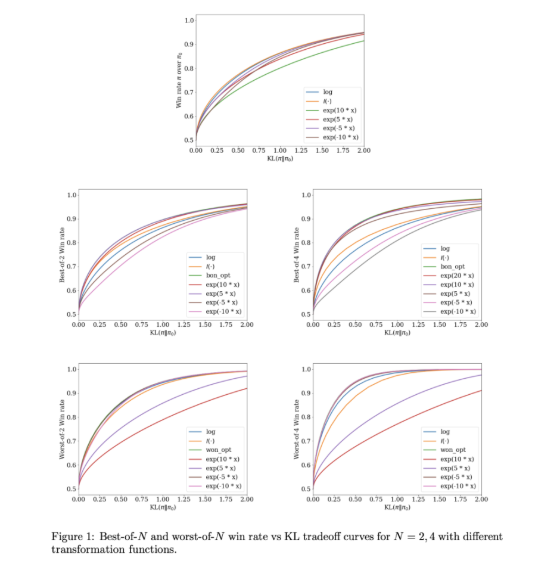
新闻热点 141 次浏览 InfAlign:提升AI模型推理效率的新框架 InfAlign:谷歌DeepMind研发的机器学习框架,通过校准强化学习提升语言模型推理胜率,显著改善AI系统对齐。 查看全文