人工智能在医疗健康领域的应用又迈出了重要步伐!哈佛大学、斯坦福大学等顶尖机构共同进行的研究表明,OpenAI的o1-preview模型在医学推理任务中展现了卓越的能力,甚至超过了人类医生。该研究不仅对模型在医学多项选择题基准测试中的表现进行了评估,还深入探讨了其在模拟真实临床场景下的诊断和管理能力,结果令人振奋。
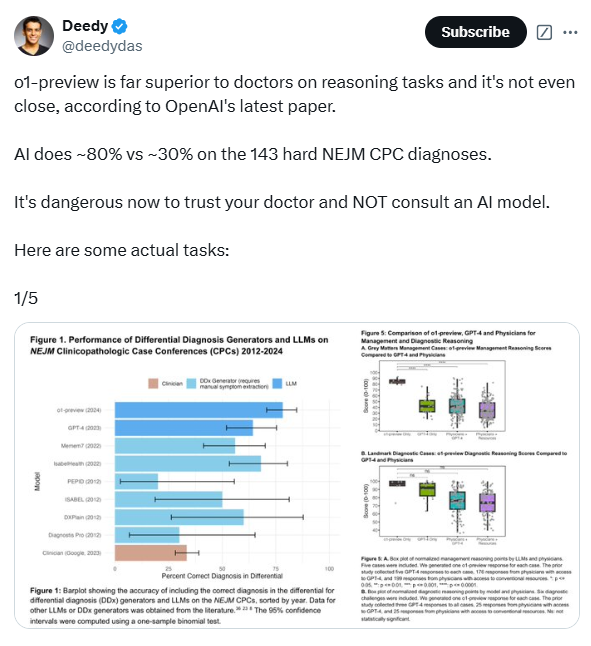
研究人员通过五个实验对o1-preview模型进行了全面评估,涉及鉴别诊断生成、诊断推理过程展示、分诊鉴别诊断、概率推理和管理推理。这些实验由医学专家采用经过验证的心理测量学方法进行评价,旨在将o1-preview的表现与之前的人类对照组和早期大型语言模型基准进行比较。结果显示,o1-preview在鉴别诊断生成以及诊断和管理推理的质量方面取得了显著提升。

在评估o1-preview生成鉴别诊断的能力时,研究人员使用了《新英格兰医学杂志》发布的临床病理讨论会(CPC)病例。结果显示,该模型在78.3%的病例中给出的鉴别诊断包含了正确诊断,在52%的病例中,首个诊断即为正确诊断。令人惊讶的是,o1-preview在88.6%的病例中给出了准确或非常接近的诊断,而之前的GPT-4模型在相同病例中的这一比例为72.9%。此外,o1-preview在选择下一步诊断测试方面也表现出色,在87.5%的病例中选择了正确的测试,11%的病例中选择的测试方案被认为是有帮助的。

为了进一步评估o1-preview的临床推理能力,研究人员使用了NEJM Healer课程中的20个临床病例。结果显示,o1-preview在这些病例中的表现明显优于GPT-4、主治医生和住院医师,在78/80的案例中获得了完美的R-IDEA评分。R-IDEA评分是一个用于评估临床推理记录质量的10分制量表。此外,研究人员还通过“Grey Matters”管理案例和“Landmark”诊断案例评估了o1-preview的管理和诊断推理能力。在“Grey Matters”案例中,o1-preview的得分显著高于GPT-4、使用GPT-4的医生和使用传统资源的医生。在“Landmark”案例中,o1-preview的表现与GPT-4相当,但优于使用GPT-4或传统资源的医生。
然而,研究也发现o1-preview在概率推理方面的表现与之前的模型相似,并未取得明显改进。在某些情况下,该模型在预测疾病概率时不如人类。研究人员还指出,o1-preview的一个局限是倾向于冗长,这可能在一定程度上提高了其在某些实验中的得分。此外,该研究主要关注模型性能,而未涉及人机交互,因此未来需要进一步研究o1-preview如何增强人机交互,以开发更有效的临床决策支持工具。
尽管如此,这项研究仍表明,o1-preview在需要复杂批判性思维的任务(如诊断和管理)中表现出色。研究人员强调,医学领域的诊断推理基准正在迅速饱和,因此需要开发更具挑战性和现实性的评估方法。他们呼吁在真实临床环境中对这些技术进行试验,并为临床医生与人工智能的协作创新做好准备。此外,还需建立健全的监督框架,以监控人工智能临床决策支持系统的广泛实施。
论文地址:https://www.arxiv.org/pdf/2412.10849






暂无评论