
在屏幕上密布的代码中,穿插着各种模型API的配置细节,桌上那杯早已冷却的咖啡见证了开发者的辛勤付出。
(adsbygoogle=window.adsbygoogle||[]).push({});
这正是众多开发者尝试构建AI应用时面临的现实:环境配置复杂、API费用高昂、文档支持不足......
"若能有一个统一平台,让所有开发者轻松使用各种AI模型,那该多好。"
这个梦想,今天终于成真。
GitHub正式推出GitHub Models服务,为全球超过1亿开发者带来了一场AI开发革命。
让我们一同深入了解这个颠覆游戏规则的新产品。
悄然而至的开发革命
在AI迅猛发展的当下,开发者的角色正经历着深刻变革。GitHub官方宣布GitHub Copilot免费计划,现已对所有用户开放!
从传统的"代码工匠"转变为"AI工程师",这一转变不仅仅是名称的更新,更是整个软件开发范式的创新。
GitHub Models的诞生,正是把握住了这一历史性的转折点。
为何选择GitHub Models?
当您需要在项目中应用AI模型时,无需再:
- 在多个平台间切换寻找合适的模型
- 为每个模型配置不同的环境和依赖
- 担忧高昂的API调用费用
- 受复杂的部署流程所困扰
GitHub Models巧妙地解决了所有这些问题。
强大模型,触手可及
豪华的模型阵容
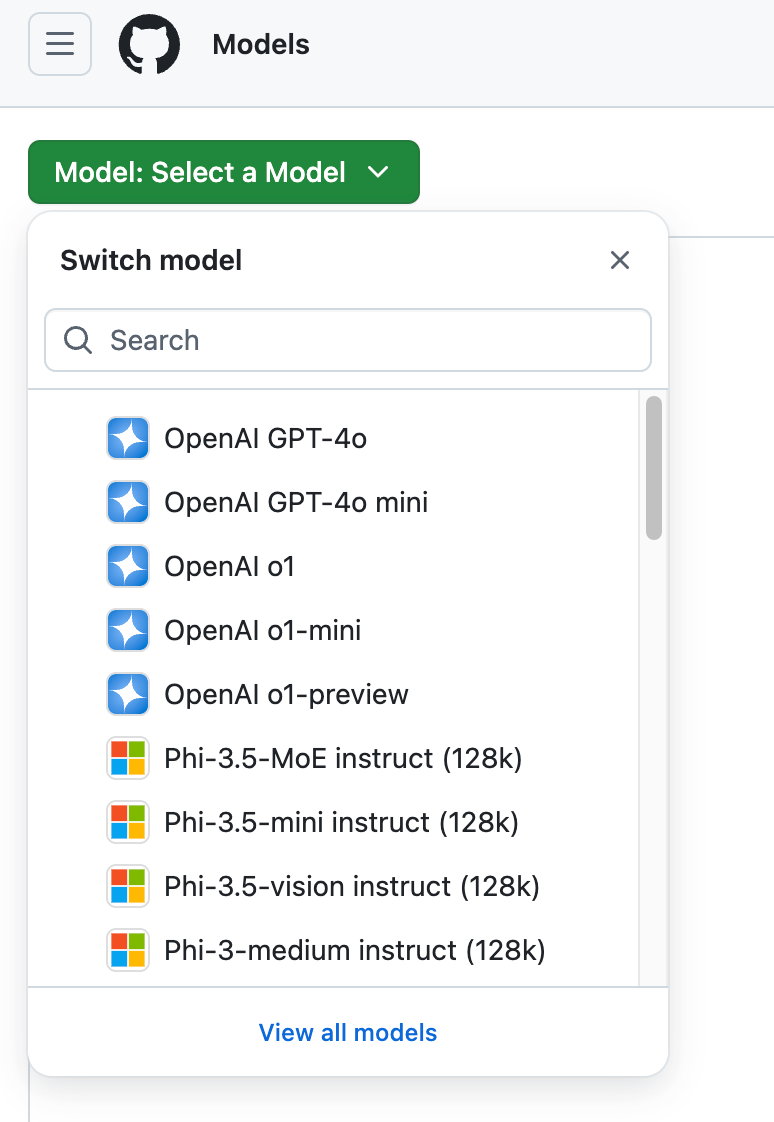
GitHub Models提供的模型库令人印象深刻:
- Llama 3.1:Meta最新开源的大模型,在多项基准测试中表现出色
- GPT-4o:OpenAI最强大的商业模型之一,支持多模态输入
- GPT-4o mini:更轻量级的版本,适合快速响应的应用场景
- Phi 3:微软的高效模型,在特定任务上表现惊人
- Mistral Large 2:以低延迟著称,适合实时应用开发
每个模型都有其独特优势,开发者可根据具体需求选择最合适的模型。
令人惊喜的使用体验
我们群里的Imdoaa,作为一家初创公司的技术负责人,分享了使用GitHub Models的经历:
"之前在选择和测试AI模型时十分头疼。要么需要支付高额费用,要么需要花费大量时间部署开源模型。使用GitHub Models后,这些问题都迎刃而解。我们可以在playground中快速对比不同模型的效果,找到最适合我们需求的那个。最棒的是,从实验到部署的整个过程都在GitHub生态系统内完成,体验非常流畅。"
深入理解三大核心优势
1. 革命性的Playground环境
Playground不仅仅是一个简单的模型测试环境,它是一个完整的AI实验室:
- 实时参数调整:
- 温度(Temperature)控制
- 最大令牌数设置
- Top-p采样调节
- 系统提示词优化
- 多模型对比:
可同时打开多个模型进行对比测试,直观地看到不同模型在相同输入下的表现差异。 - 历史记录保存:
所有的实验过程都会被记录,方便后续回顾和优化。
2. 无缝的Codespaces集成
Codespaces的集成让开发过程变得异常流畅:
- 预配置环境:
所有必要的依赖和配置都已准备就绪,开箱即用。 - 多语言支持:
提供Python、JavaScript、Java等主流语言的示例代码和SDK。
- 版本控制:
直接与GitHub仓库集成,代码变更管理更加便捷。
3. 企业级部署保障
通过Azure AI的支持,企业级部署变得简单可靠:
- 全球化部署:
超过25个Azure区域可供选择,确保全球用户的访问速度。 - 安全合规:
符合企业级安全标准,支持数据加密和访问控制。 - 可扩展性:
根据需求自动扩展资源,确保服务稳定性。
深度解析使用配额
不同版本的使用配额设计体现了GitHub的产品策略:
免费版和Copilot Individual
- 每分钟请求:10次
- 每日配额:50次
- 令牌限制:
- 输入:8000
- 输出:4000
- 并发请求:2个
此配额适合个人开发者进行项目验证和学习。
Copilot Business
- 保持相同的并发和令牌限制
- 每日请求提升至100次
- 适合小型团队的开发需求
Copilot Enterprise
- 每分钟请求:15次
- 每日配额:150次
- 更大的令牌限制:
- 输入:16000
- 输出:8000
- 并发请求:4个
- 适合企业级应用开发
实践锦囊
开发效率提升技巧
- 智能缓存策略
# 示例代码:实现简单的结果缓存 import hashlib import json class ModelCache: def __init__(self): self.cache = {} def get_cache_key(self, prompt, params): data = f"{prompt}_{json.dumps(params, sort_keys=True)}" return hashlib.md5(data.encode()).hexdigest() def get_or_compute(self, prompt, params, model_func): key = self.get_cache_key(prompt, params) if key in self.cache: return self.cache[key] result = model_func(prompt, params) self.cache[key] = result return result - 批量处理优化
合理组织请求批次,避免频繁的API调用。 - 错误处理最佳实践
实现智能重试机制,处理临时性故障。
安全性建议
- 访问令牌管理
- 定期轮换Personal Access Token
- 使用最小权限原则
- 避免在代码中硬编码令牌
- 数据安全
- 在发送到模型前进行数据脱敏
- 实现数据访问审计
- 定期检查安全日志
展望
GitHub CEO Thomas Dohmke的愿景是在未来几年内帮助全球达到10亿开发者的目标。这个雄心壮志背后,是对AI民主化的坚定信念。
立即开启AI工程师之旅
- 申请准备
- 访问GitHub Models官方页面
- 提交等待列表申请
- 准备GitHub账号和个人访问令牌
- 环境配置
import OpenAI from "openai"; const token = process.env["GITHUB_TOKEN"]; const client = new OpenAI({ baseURL: "https://models.inference.ai.azure.com", apiKey: token }); - 开始实验
- 在playground中测试不同模型
- 使用示例代码快速启动项目
- 逐步扩展应用功能
结语
AI技术的发展正在重塑软件开发的未来。GitHub Models的推出,不仅仅是一个新产品的诞生,更是一个新时代的开始。它让每一个开发者都有机会参与到AI革命中来,用创新的想法和实践来改变世界。
现在,摆在你面前的不再是要不要开始AI开发的问题,而是如何更好地利用GitHub Models这个强大的平台,在AI工程师的道路上走得更远。机会就在眼前,你准备好了吗?
正如一位资深开发者所说:"GitHub Models不仅仅是一个工具,它是一把开启AI时代的钥匙。有了它,每个开发者都能成为AI工程师,每个想法都能变成现实。"
现在,是时候开始你的AI开发之旅了。





暂无评论