摩尔线程在深度计算领域再下一城!今日,该公司重磅推出,正式开源MT-MegatronLM与MT-TransformerEngine两大AI框架,此举将为我国计算基础设施注入强劲动力。这两大框架通过融合FP8混合训练策略与高性能算子库,在国产全功能GPU上实现了混合并行训练与推理,大幅提升了大型模型训练的效率和稳定性。
特别为全功能GPU量身打造的MT-MegatronLM框架,支持密集模型、多模态模型及MoE(混合专家)模型的高效训练,满足AI领域多样化的训练需求。而MT-TransformerEngine专注于Transformer模型的训练与推理优化,通过算子融合、并行加速策略等技术,有效挖掘了摩尔线程全功能GPU的高密度计算潜力,显著提升了内存密集型算子的效率。
这两大框架的技术突破,主要体现在硬件适配与算法创新的深度协同。首先,它们支持多种类型模型的混合并行训练,灵活应对复杂运算场景;其次,结合摩尔线程GPU原生支持的FP8混合精度训练策略,显著提升训练效率;第三,通过高性能算子库muDNN与通信库MCCL的深度集成,系统性优化了计算密集型任务与多卡协同的通信开销;同时,结合开源Simumax库,自动进行并行策略搜索,最大化并行训练性能;此外,框架内置的rewind异常恢复机制,可自动回滚至最近稳定节点继续训练,大幅提升了大规模训练的稳定性;最后,两个框架兼容GPU主流生态,保障现有生态的平滑迁移,并为开发者构建自有的AI技术栈提供底层支撑。
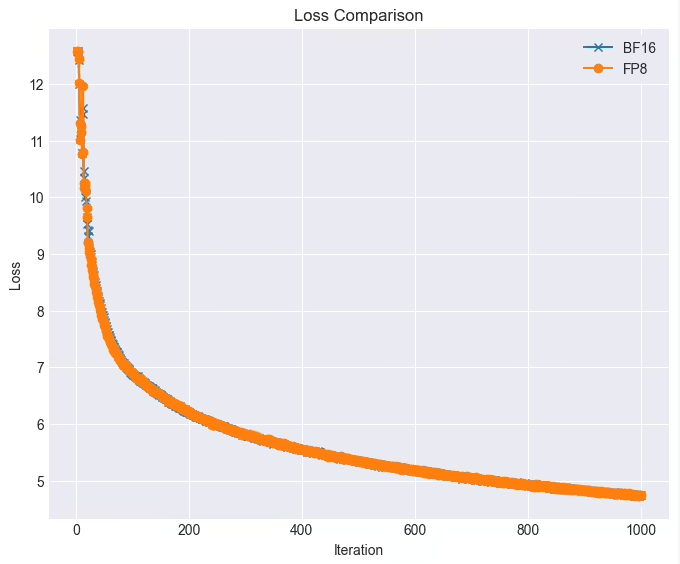
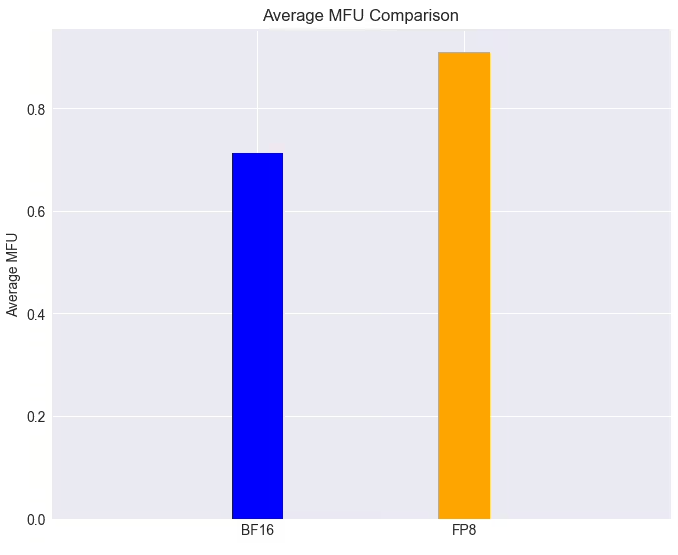
在实际应用中,这两大框架的表现令人瞩目。在全功能GPU集群上,Llama38B模型的训练任务利用FP8技术,在loss几乎无损的情况下,MFU(模型吞吐利用率)达到90%以上,相比原来提升了28%的训练速度。此外,摩尔线程已深度集成并开源对DeepSeek并行算法DualPipe的高效支持,MT-DualPipe接入MT-Megatron框架和MT-TransformerEngine框架后,成功复现了DeepSeek V3训练流程,支持MLA、MTP及多种专家平衡策略。通过多种Transformer算子融合技术,这些框架显著提升了内存带宽利用率,有效缓解了memory bound瓶颈,进一步释放了国产GPU的硬件潜力。
摩尔线程表示将持续优化这两大框架,并计划引入一系列新功能:包括Dual Pipe/ZeroBubble并行策略以降低气泡率,提升并行训练效率;多种独创的FP8优化策略以提高训练性能和稳定性;异步checkpoint策略以提高训练过程中的容错能力和效率;优化后的重计算策略以减少计算和显存开销,提高训练速度;独创的容错训练算法以增强训练过程中的容错能力;以及集成摩尔线程FlashMLA和DeepGemm库以进一步释放摩尔线程GPU的算力和FP8计算能力,全面提升计算性能和效率。
这一系列技术突破与开源举措,不仅展示了摩尔线程在AI算力领域的实力,更为国产AI基础设施的发展开辟了新的可能性,让我们期待其在AI模型训练领域带来更多突破。



暂无评论