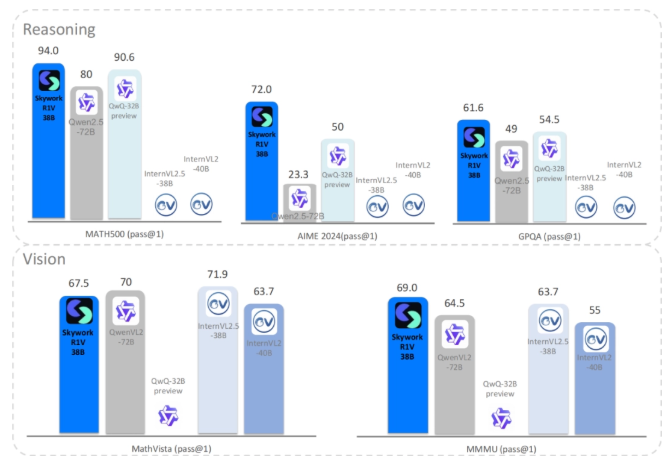
2025年3月4日,北京智谱华章科技有限公司发布了首个支持汉字生成的开源文生图模型——CogView4。在DPG-Bench基准测试中,CogView4综合评分位列第一,成为开源文生图模型领域的顶尖之作。该模型遵循Apache2.0协议,是首个采用此协议的图像生成模型。
CogView4拥有卓越的复杂语义对齐和指令跟随能力,可接受任意长度的中英双语输入,并生成相应分辨率的图像。它不仅生成高质量的图像,还能自然地融入汉字,满足广告、短视频等领域的创意需求。技术上,CogView4利用具有双语能力的GLM-4encoder,通过中英双语图文训练,实现了双语提示词输入功能。

该模型支持任意长度的提示词输入,生成任意分辨率的图像,极大提高了创作自由度和训练效率。CogView4采用二维旋转位置编码(2D RoPE)来建模图像位置信息,并通过内插位置编码支持不同分辨率的图像生成。此外,模型采用Flow-matching方案进行扩散生成建模,结合参数化的线性动态噪声规划,以适应不同分辨率图像的信噪比需求。
在架构设计上,CogView4继承自上一代的Share-param DiT架构,并为文本和图像模态分别设计了独立的自适应LayerNorm层,以实现模态间的高效适配。模型采用多阶段训练策略,包括基础分辨率训练、泛分辨率训练、高质量数据微调以及人类偏好对齐训练,确保生成的图像既美观又符合人类审美。
CogView4突破了传统固定token长度的限制,允许更高的token上限,并显著减少了训练过程中的文本token冗余。当训练caption的平均长度在200-300token时,与固定512token的传统方案相比,CogView4减少了约50%的token冗余,并在模型递进训练阶段实现了5%-30%的效率提升。
此外,CogView4支持Apache2.0协议,未来将陆续增加ControlNet、ComfyUI等生态支持,并即将推出全套的微调工具包。
开源仓库地址:
https://github.com/THUDM/CogView4
模型仓库:
https://huggingface.co/THUDM/CogView4-6B
https://modelscope.cn/models/ZhipuAI/CogView4-6B



暂无评论