专家混合和稀疏注意力使几乎无限的上下文成为可能,让RAG AI Agent无需上下文限制即可消化整个代码库和文档。
(adsbygoogle = window.adsbygoogle || []).push({});
📌 长上下文注意力的挑战
序列变大时,Transformers仍面临沉重的计算负担。默认的注意力模式将每个token与所有token比较,导致计算成本呈二次方增长。阅读整个代码库、多章节文档或大量法律文本时,这种开销成为问题。
📌 MoBA
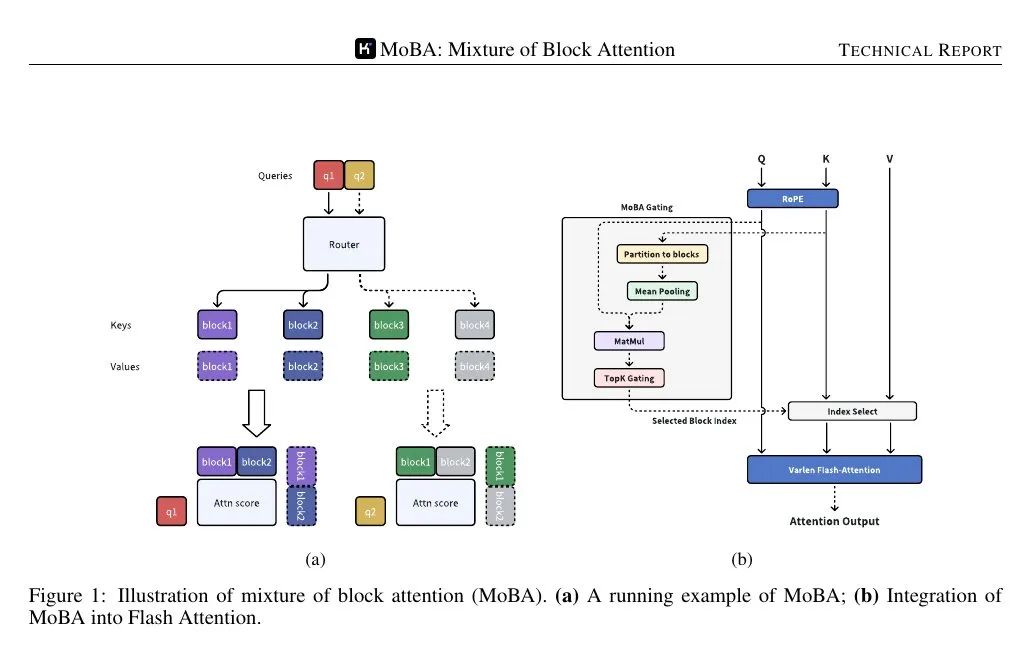
MoBA(Mixture of Block Attention)将专家混合应用于注意力机制。模型将输入序列划分为多个块,一个可训练的门控函数计算每个查询token与每个块的相关性得分。仅得分最高的块用于注意力计算,避免对完整序列的每个token的注意。
块通过将序列分割成相等跨度定义。每个查询token查看每个块中键的汇聚表示,然后对其重要性进行排序,选择几个块进行详细注意力计算。包含查询的块始终被选中。因果掩码确保token不会看到未来的信息,保持从左到右的生成顺序。
📌 在稀疏注意力与完整注意力之间无缝切换
MoBA替代了标准的注意力机制,但未改变参数数量。它与标准Transformer接口兼容,可在不同层或训练阶段之间切换稀疏和完整注意力。一些层可能保留完整注意力,而大多数层则使用MoBA来降低计算成本。
📌 这适用于更大的Transformer堆栈,通过替换标准的注意力调用。门控机制确保每个查询仅关注一小部分块。因果性通过过滤掉未来的块以及在当前块内应用局部掩码来处理。
📌 下图为查询仅被路由到少数几个“专家”块的键/值,而非整个序列。门控机制将每个查询分配到最相关的块,从而将注意力计算的复杂度从二次方降低到子二次方。
📌 门控机制计算每个查询与每个块的凝聚表示之间的相关性得分。然后,它会为每个查询选择得分最高的前k个块,无论这些块在序列中的位置有多远。
由于每个查询仅处理少数几个块,因此计算仍然是子二次方的,但如果门控得分显示出较高的相关性,模型仍然可以跳转到远离当前块的token。
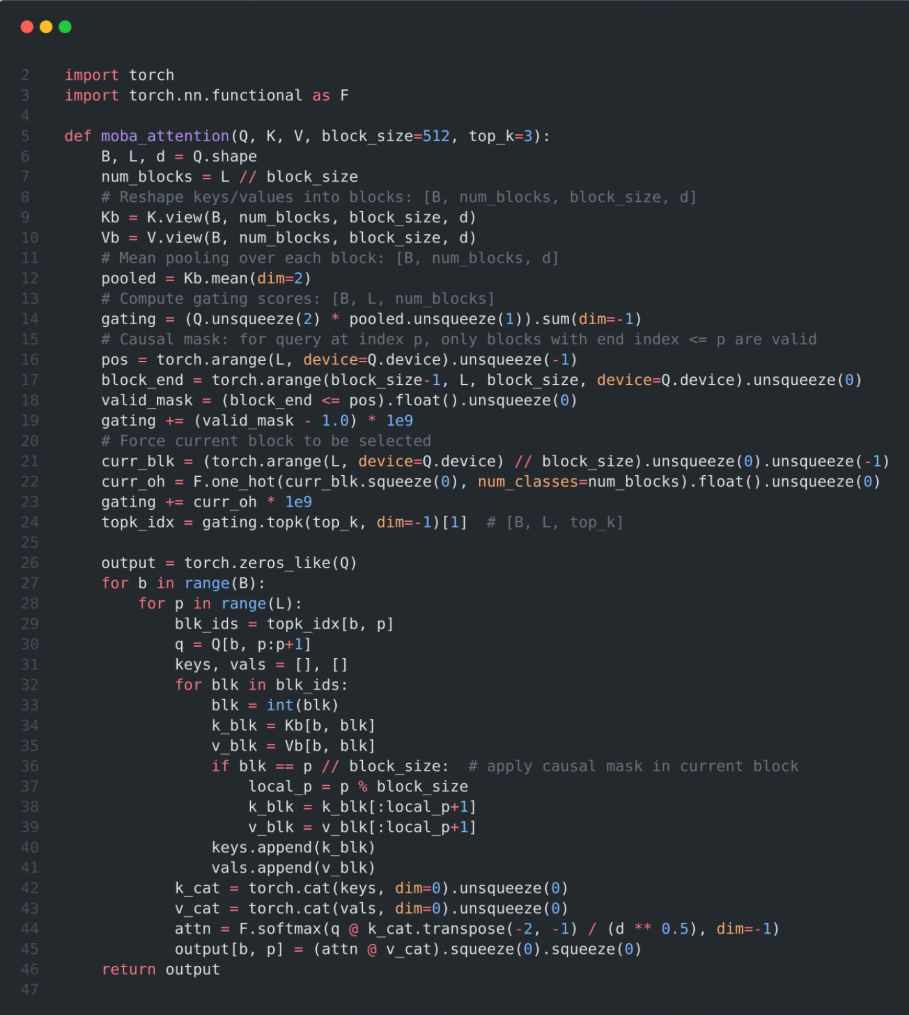
PyTorch 实现
伪代码将键和值划分为多个块,计算每个块的均值池化表示,并通过将查询与池化表示相乘来计算门控得分。
然后,它应用因果掩码,以确保查询不能关注未来的块,使用top-k操作符为每个查询选择最相关的块,并将数据组织起来以进行高效的注意力计算。
📌 FlashAttention分别应用于自注意力块和MoBA选定的块,最后使用在线softmax将输出合并。
📌 最终结果是一个稀疏注意力机制,它保留了因果结构并捕获了长距离依赖关系,同时避免了标准注意力的完整二次方计算成本。

这段代码将专家混合与稀疏注意力结合,使每个查询仅关注少数几个块。
门控机制为每个块与查询评分,并选择前k个“专家”,从而减少键/值比较的数量。
这使得注意力的计算开销保持在子二次方水平,能够在不增加计算或内存负担的情况下处理极长的输入。
同时,门控机制确保查询在必要时仍能关注到远距离的token,从而保留了Transformer对全局上下文的处理能力。
这种基于块和门控的策略正是MoBA在LLM中实现近无限上下文的方式。
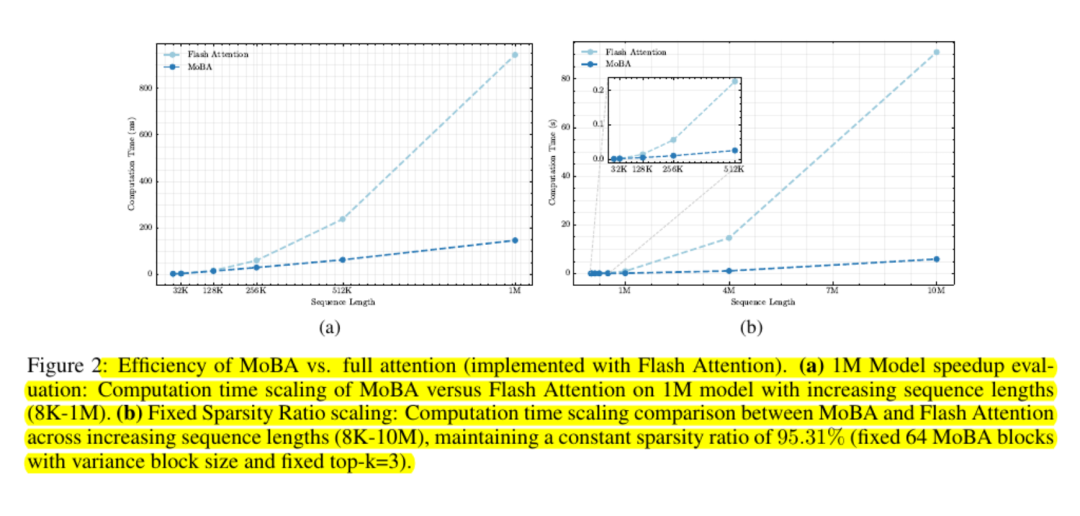
实验观察
使用MoBA的模型在语言建模损失和下游任务性能上几乎与完整注意力相当。即使在数十万或数百万个token的上下文长度下,结果仍保持一致。
可扩展性测试表明其成本曲线是子二次方的。研究人员报告,在一百万个token的情况下,速度提高了最多六倍,且在该范围之外的增益更大。
MoBA通过避免使用完整的注意力矩阵并利用标准的GPU内核进行基于块的计算,保持了内存友好性。
最终观察
MoBA通过一个简单的思路减少了注意力开销:让查询学习哪些块是重要的,并忽略其他所有块。
它保留了基于标准softmax的注意力接口,并避免强制使用僵化的局部模式。许多大型语言模型可以以插拔式的方式集成这一机制。
这使得MoBA对于需要处理极长上下文的工作负载非常有吸引力,如扫描整个代码库或总结庞大的文档,而无需对预训练权重进行重大修改或消耗大量的重训练开销。






暂无评论