在人工智能领域,语言模型的迅猛发展使得语音理解语言模型(SULMs)备受瞩目。近期,西北工业大学ASLP实验室推出了开放语音理解模型OSUM,致力于在资源有限的环境下,高效地训练和应用语音理解模型,以促进学术研究和创新。
视频展示:[观看视频](https://upload.chinaz.com/video/2025/0220/6387566599778256079365136.mp4)
OSUM模型整合了Whisper编码器和Qwen2语言模型,覆盖了包括语音识别(ASR)、带时间戳的语音识别(SRWT)、语音事件检测(VED)、语音情感识别(SER)、说话风格识别(SSR)、说话人性别分类(SGC)、说话人年龄预测(SAP)以及语音转文本聊天(STTC)在内的8种语音任务。通过采用ASR+X训练策略,该模型在执行特定任务的同时,能够高效稳定地优化语音识别,增强多任务学习的能力。
OSUM模型的发布不仅关注性能,还强调透明度。其训练方法和数据准备过程均已公开,为学术界提供宝贵参考。据技术报告v2.0介绍,OSUM的训练数据量已增至50.5K小时,较之前44.1K小时有显著提升。其中,包含3000小时的语音性别分类数据和6800小时的说话人年龄预测数据,这些数据的扩展使得模型在各项任务中的表现更为出色。
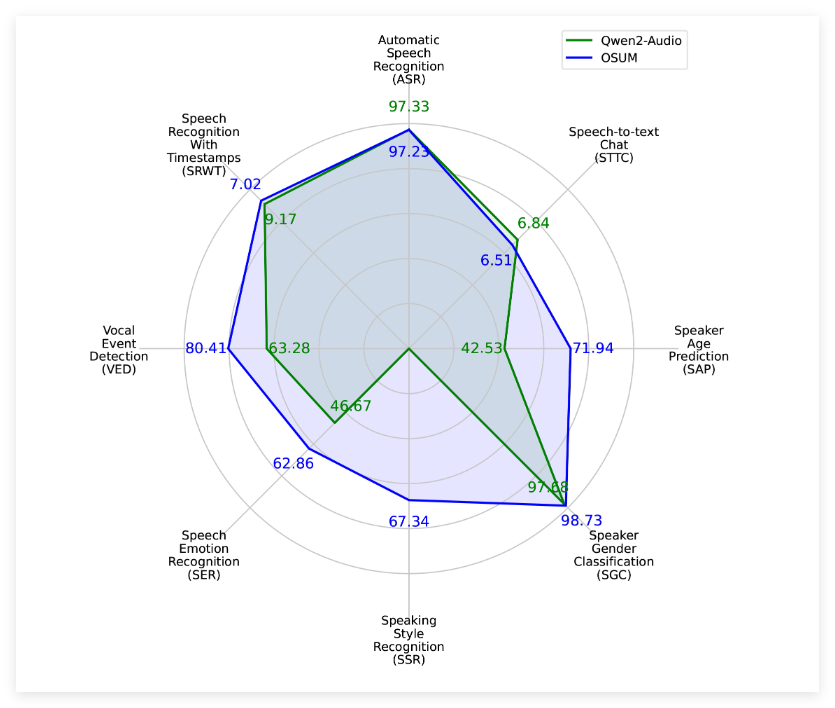
评估结果显示,OSUM在多项任务上超越了Qwen2-Audio模型,即便在计算资源和训练数据方面存在明显劣势。评估结果不仅涵盖了公共测试集,还包括内部测试集,充分展示了OSUM模型在语音理解任务上的卓越性能。
图片展示:[查看图片](https://www.qewen.com/wp-content/uploads/2025/02/1740042796-20250220091316-67b6f22c0eb78.png)
西北工业大学ASLP实验室表示,OSUM的目标是通过开放的研究平台,推动先进语音理解技术的发展。科研人员和开发者可自由使用该模型的代码和权重,甚至可用于商业目的,加速技术的应用与推广。
项目入口:[访问项目](https://github.com/ASLP-lab/OSUM?tab=readme-ov-file)
🌟 OSUM模型融合Whisper编码器与Qwen2语言模型,支持多种语音任务,助力多任务学习。
📊 技术报告v2.0中,OSUM训练数据量增至50.5K小时,提升了模型性能。
🆓 该模型代码和权重在Apache2.0许可下开放使用,鼓励学术界和工业界的广泛应用。




暂无评论