
中文大模型「AI搜索」(SuperCLUE-AISearch)基准测评正式发布,旨在深入评估大模型结合搜索的能力。此次测评不仅关注大模型的基础能力,还重点考察其在实际场景中的表现。测评内容涵盖五项基础能力,包括信息检索能力、最新信息获取能力等,以及十一种场景应用,例如新闻和生活应用,全面检验模型在不同基础能力和场景应用任务中的表现。有关测评方案的详细信息,请查阅:「AI搜索」基准测评方案发布。本次评测涵盖了国内外14个具有代表性的大模型的AI搜索能力,以下是详细测评报告。
AI搜索测评摘要
(adsbygoogle=window.adsbygoogle||[]).push({});
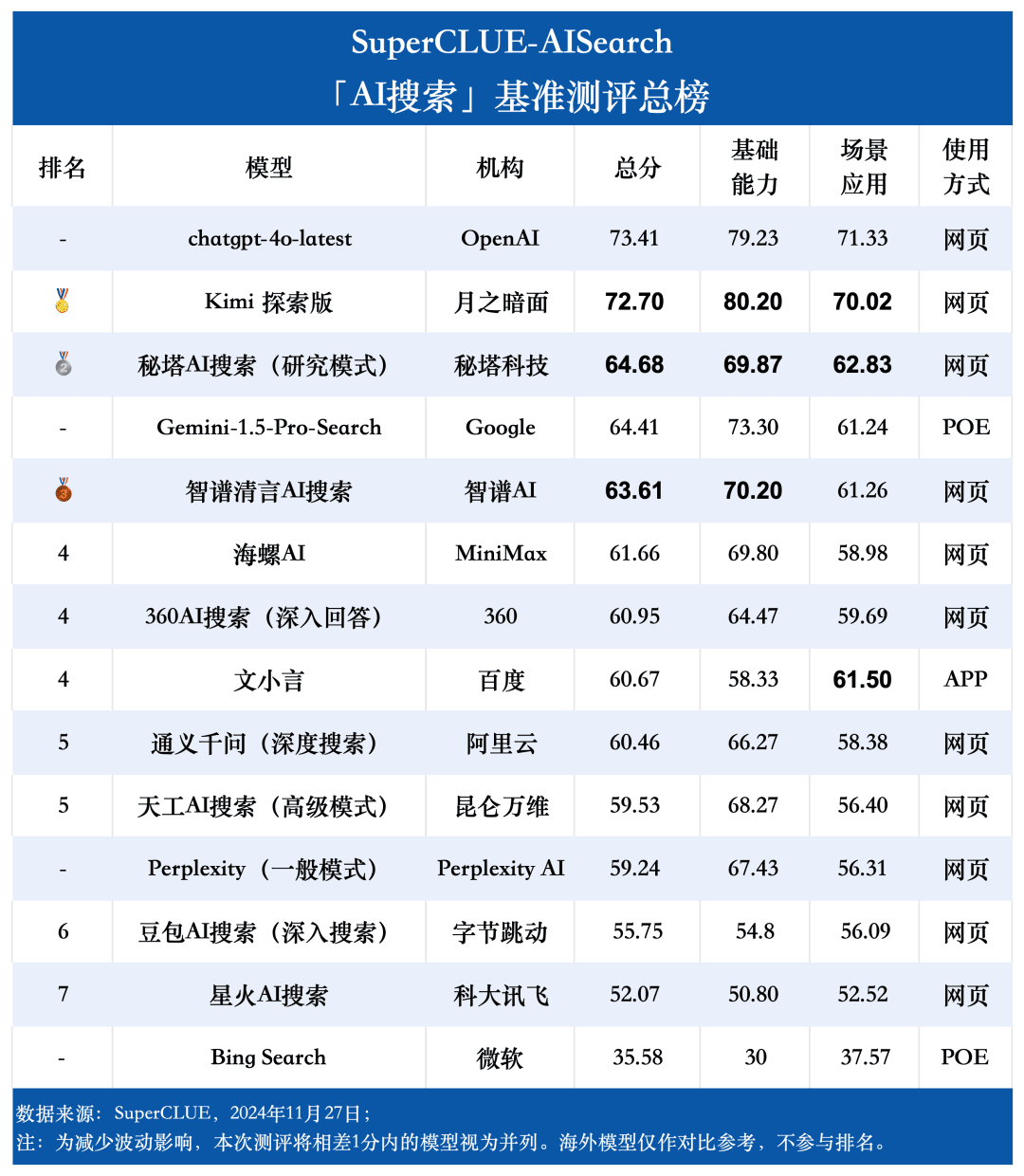
测评要点1:在AI搜索榜单中,chatgpt-4o-latest名列前茅,Kimi探索版紧随其后,两者之间的分差仅为0.71分。本次测评中,chatgpt-4o-latest以优异的表现获得了73.41分,领先其他参评模型。同时,国内大模型Kimi探索版在购物类和文化类题目方面表现突出,展现了卓越的AI搜索能力和综合性能。
测评要点2:国内大模型整体表现抢眼,部分超越国际同行。从测评结果来看,秘塔AI搜索(研究模式)、智谱清言AI搜索和海螺AI等国内模型在综合表现上颇具竞争力,与海外大模型Gemini-1.5-Pro-Search不相上下。此外,综合成绩处于中游的国内模型如360AI搜索(深入回答)、文小言和通义千问(深度搜索)等在表现上也相差无几。
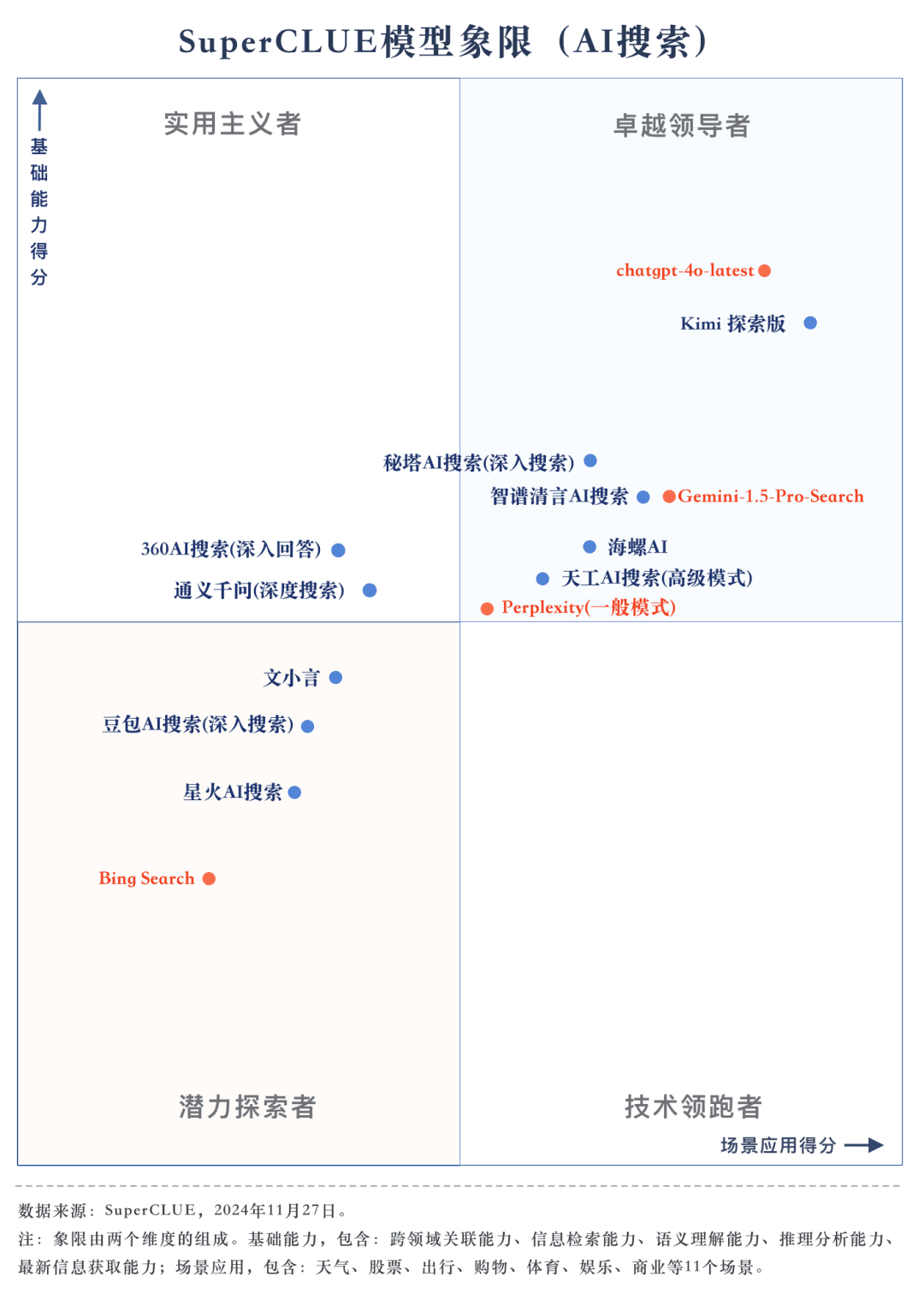
测评要点3:在不同场景应用中,各模型展现出了不同程度的能力。在AI搜索测评中,我们关注了各大模型在不同场景应用下的表现。国内大模型在科技、文化、商业和娱乐领域表现较为出色,能够及时捕捉信息并展现出卓越的信息检索与整合能力。然而,在股票、体育等场景应用中,国内大模型仍有待提升。
榜单概览
SuperCLUE-AISearch介绍
SuperCLUE-AISearch是中文AI搜索模型综合测评集,旨在为中文领域提供AI搜索模型能力评估的参考。
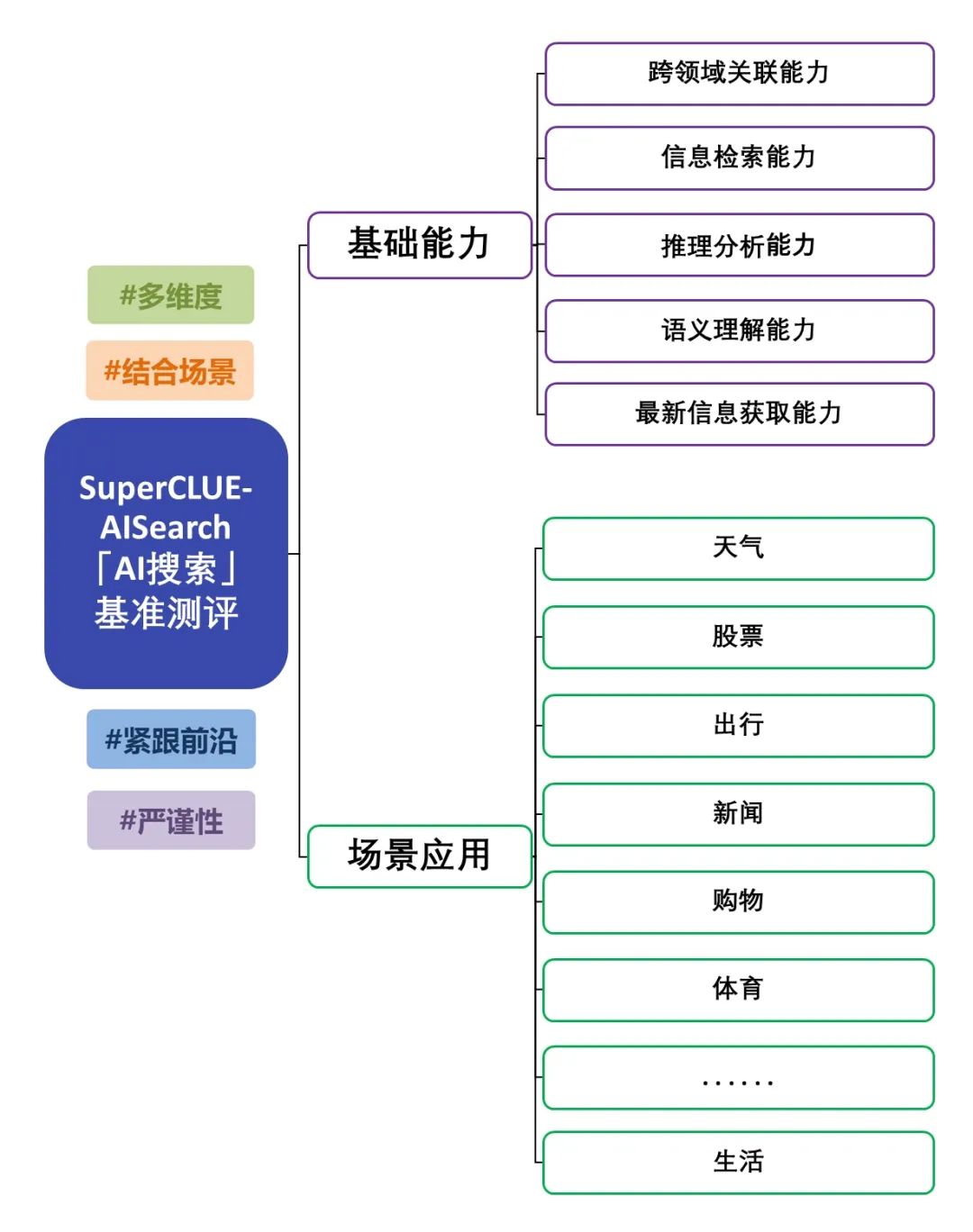
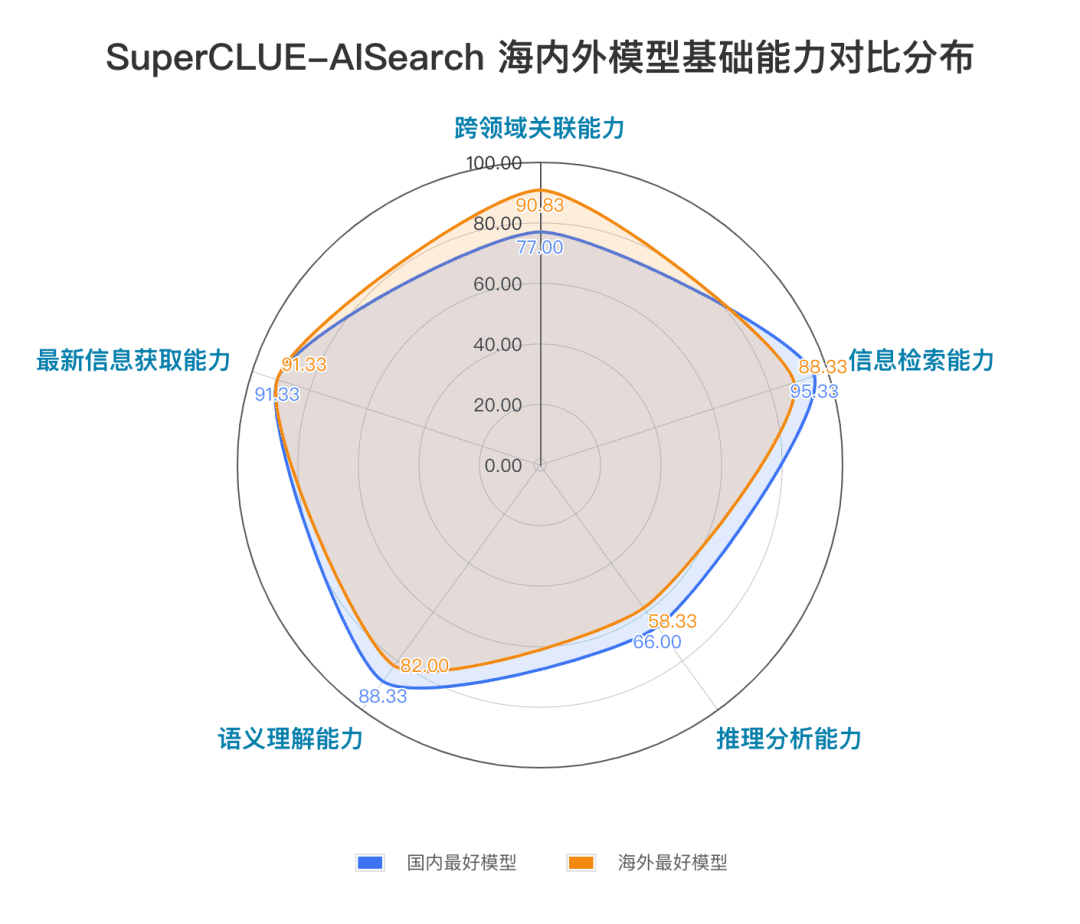
基础能力包括AI搜索任务中需具备的五项能力:跨领域关联能力、信息检索能力、语义理解能力、最新信息获取能力和推理能力。
场景应用包括AI搜索任务中常见的11种场景:天气、股票、出行、新闻、购物、体育、娱乐、教育、旅行、商业、文化、科技、医疗和生活。
测评方法
本次测评参考了SuperCLUE的细粒度评估方式,构建了专用测评集,对每个维度进行细致评估,并提供详细反馈信息。
1)测评集构建
中文prompt构建流程为:1. 参考现有prompt;2. 撰写中文prompt;3. 测试;4. 修改并确定中文prompt。针对每个维度构建专用测评集。
2)评分方法
评估流程始于模型与数据集的交互,模型需根据提供的问题进行理解和回答。
评估标准涵盖思维过程、解题策略和反思调整等多个维度。
评分规则结合自动化定量评分与专家复核,确保评估的科学性和公正性。
3)评分标准
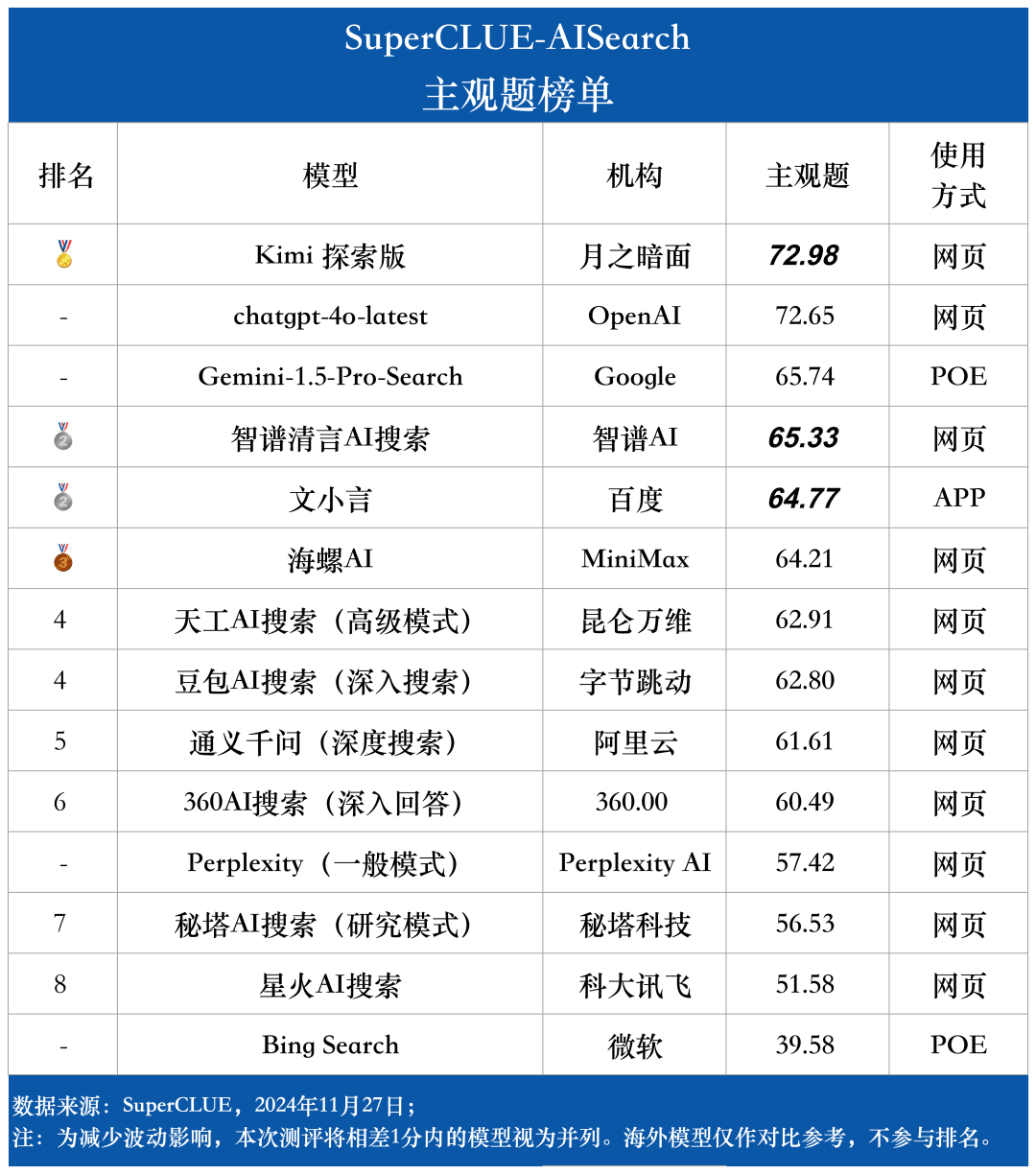
针对各大模型在测评任务上的表现,我们使用两套评估标准分别评估测评集中的主观题和客观题。这些标准在评估中赋予不同权重,以全面反映大模型在AI搜索任务中的表现。
SuperCLUE-AISearch的主观题评分标准满分为5分,评估维度为信息实用性、分析准确性和表达清晰度,分别占60%、20%和20%。客观题评分标准同样满分为5分,评估维度为信息准确性和表达清晰度,权重为80%和20%。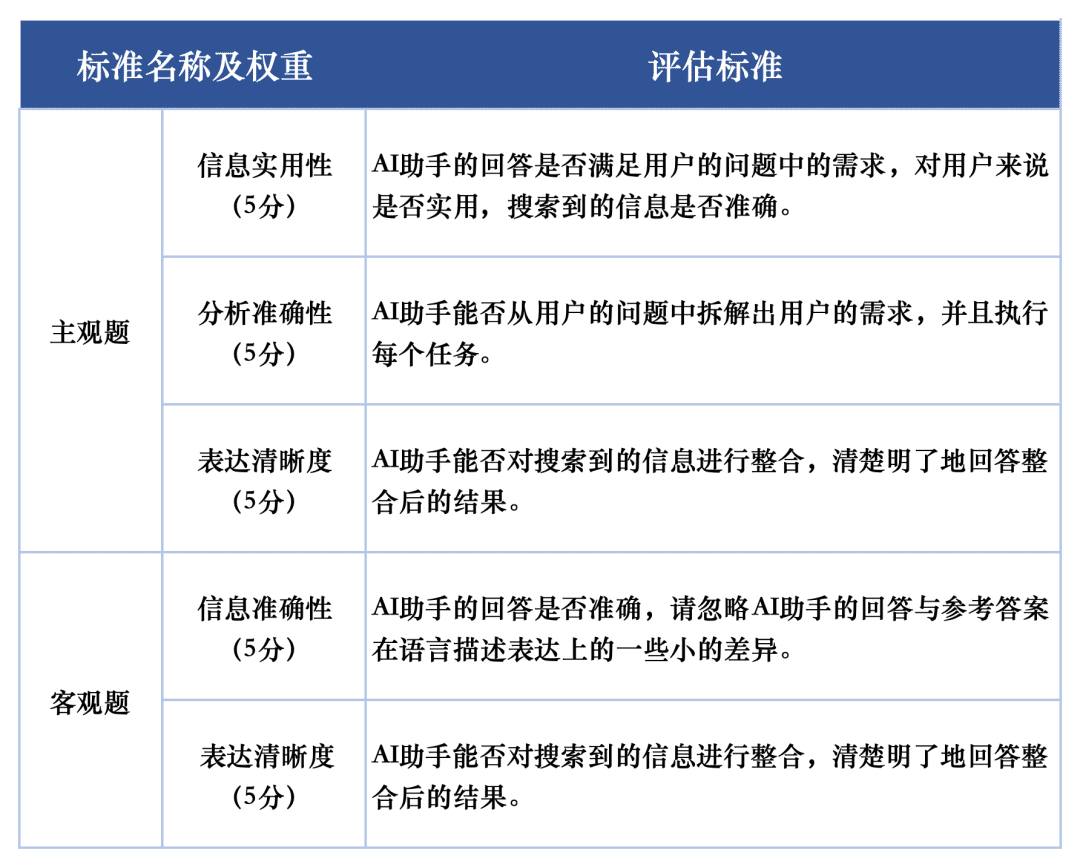
测评示例
提示词Prompt:神舟十九号载人飞船是在何时何地发射的,此次的航天员都有谁?
参考答案:10月30日凌晨,神舟十九号载人飞船在酒泉卫星发射中心成功发射。参与此次任务的航天员为蔡旭哲、宋令东和王浩泽三名航天员。
模型回答:

超级模型(chatgpt-4o-latest)裁判:
对该答案的评估如下:
AI助手的回答准确提供了神舟十九号载人飞船的发射时间、地点和航天员名单。但回答中未提及此次任务的主要目标和内容,未能全面满足用户对任务细节的了解需求。航天员的个人简介内容虽然详细,但可能超出了用户的关注范围。因此,建议在回答中增加关于任务目标和主要任务的简要说明,以更好地满足用户需求。1. 信息实用性(5分):
AI助手提供了发射时间、地点和航天员名单,满足用户的基本信息需求。虽然未提及任务的主要目标,但依然是有用的信息,因此得分4分。
得分:4/52. 分析准确性(5分):
AI助手准确地提取了发射时间、地点和航天员名单等重要信息,并提供了详细的个人简介。由于未涉及任务目标,分析准确性得分为4分。
得分:4/53. 表达清晰度(5分):
AI助手的回答结构清晰,信息组织合理且易于理解。个人简介部分详细,因此表达清晰度得分为5分。
得分:5/5综合得分 = 4*0.6 + 4*0.2 +5*0.2 = 4.2综合来看,AI助手的回答综合得分为4.2分(满分5分)。
参评模型
为综合评估当前国内外大模型在AI搜索能力的发展水平,本次测评选取了4个海外模型和10个国内代表性模型。
考虑到国内外众多大型模型普遍提供包括普通版和深度探索版在内的多种版本,本次模型评选中,我们采取统一标准:若某模型配备更深入的搜索或分析版本,我们将选择能力最强的版本进行评估。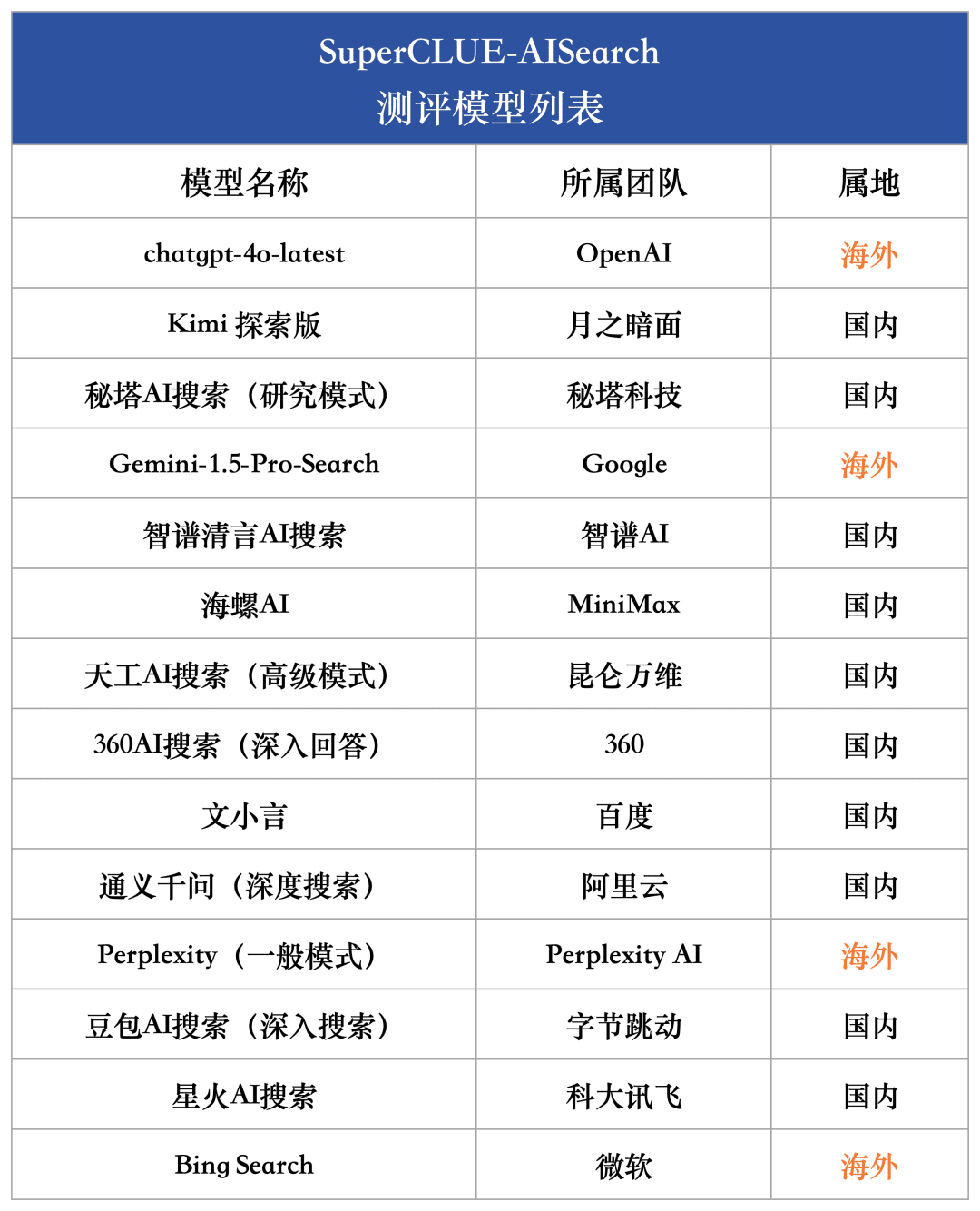
测评结果
总榜单 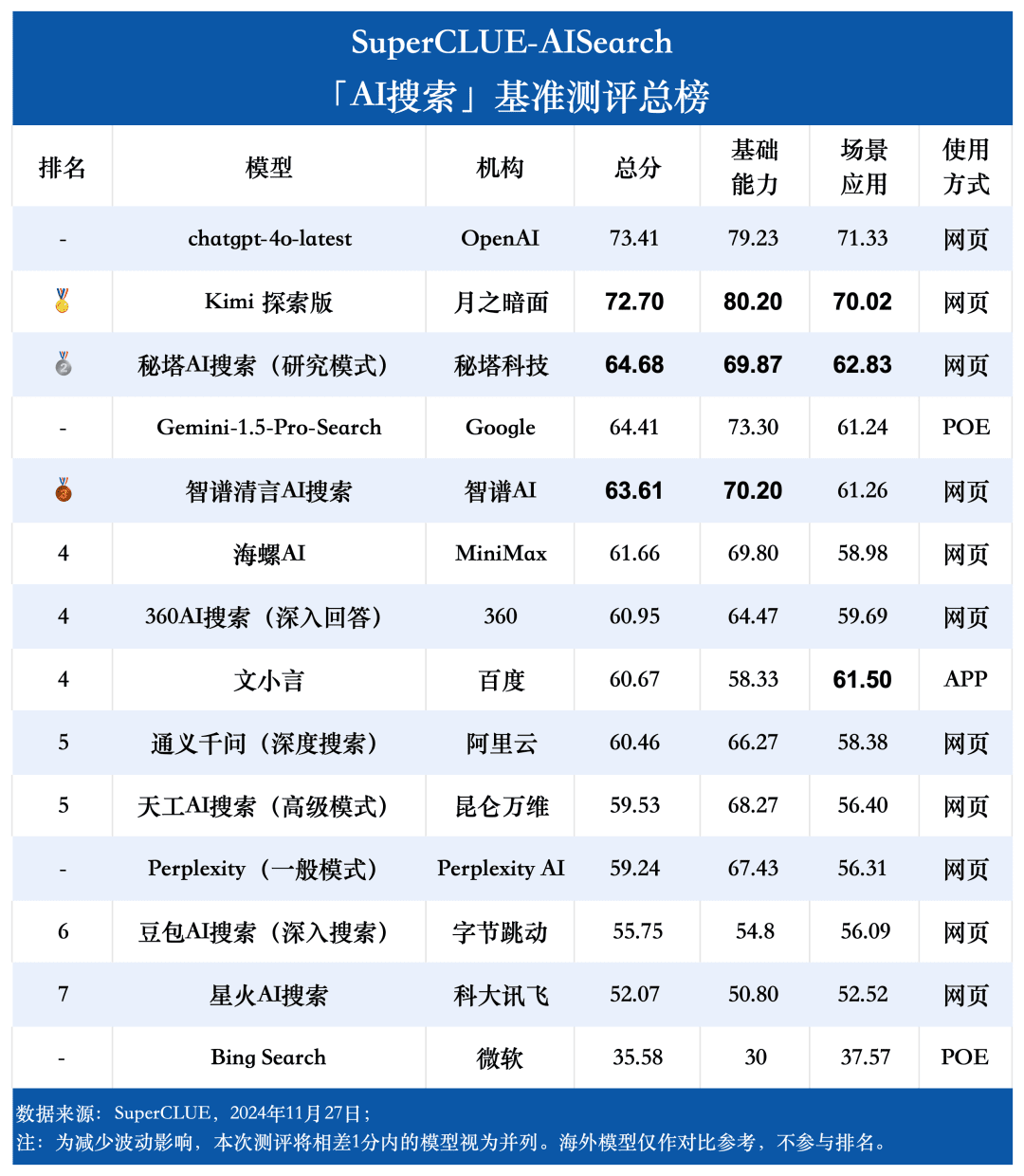
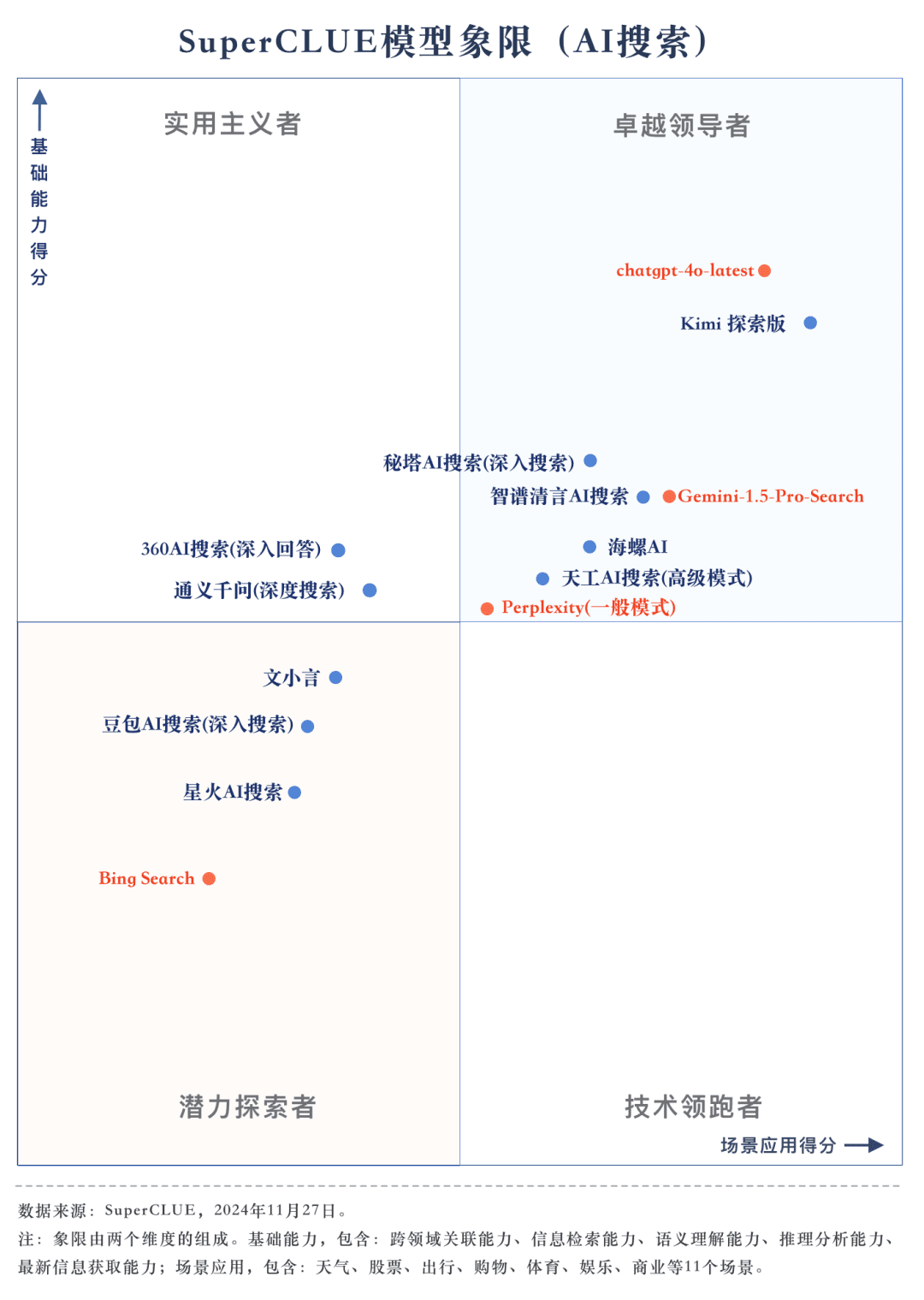
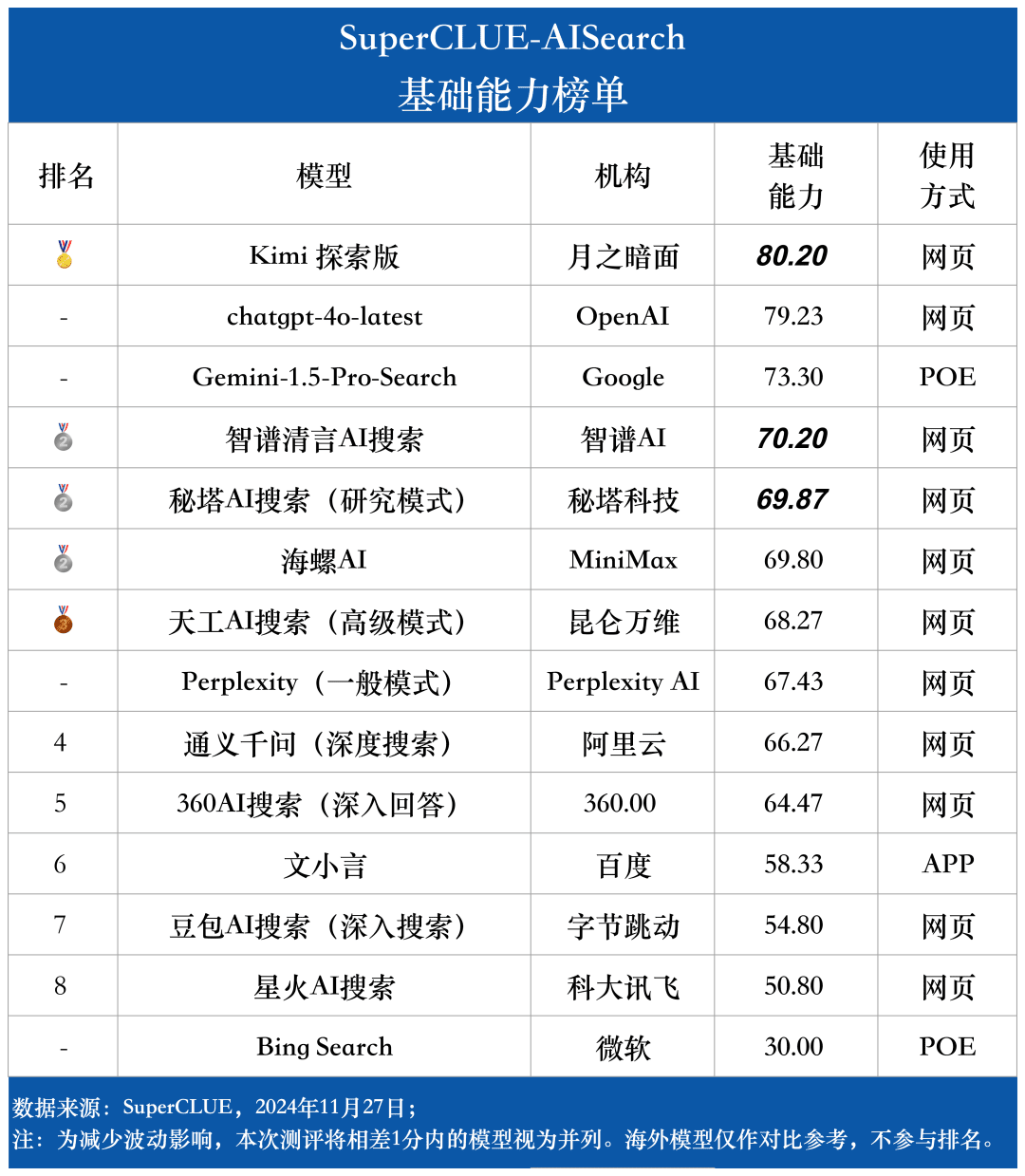
基础能力榜单
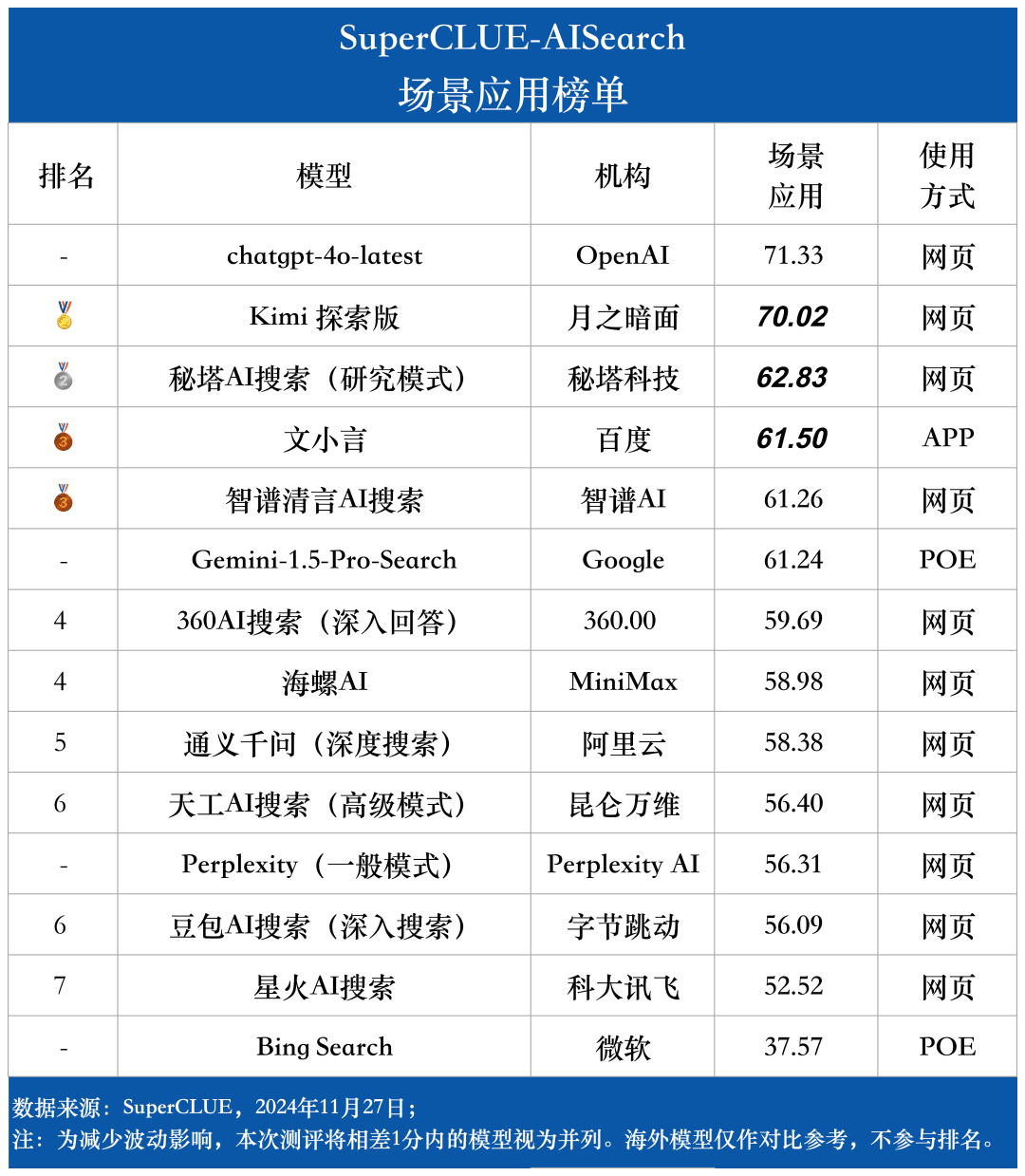
场景应用榜单
主观题榜单
客观题榜单 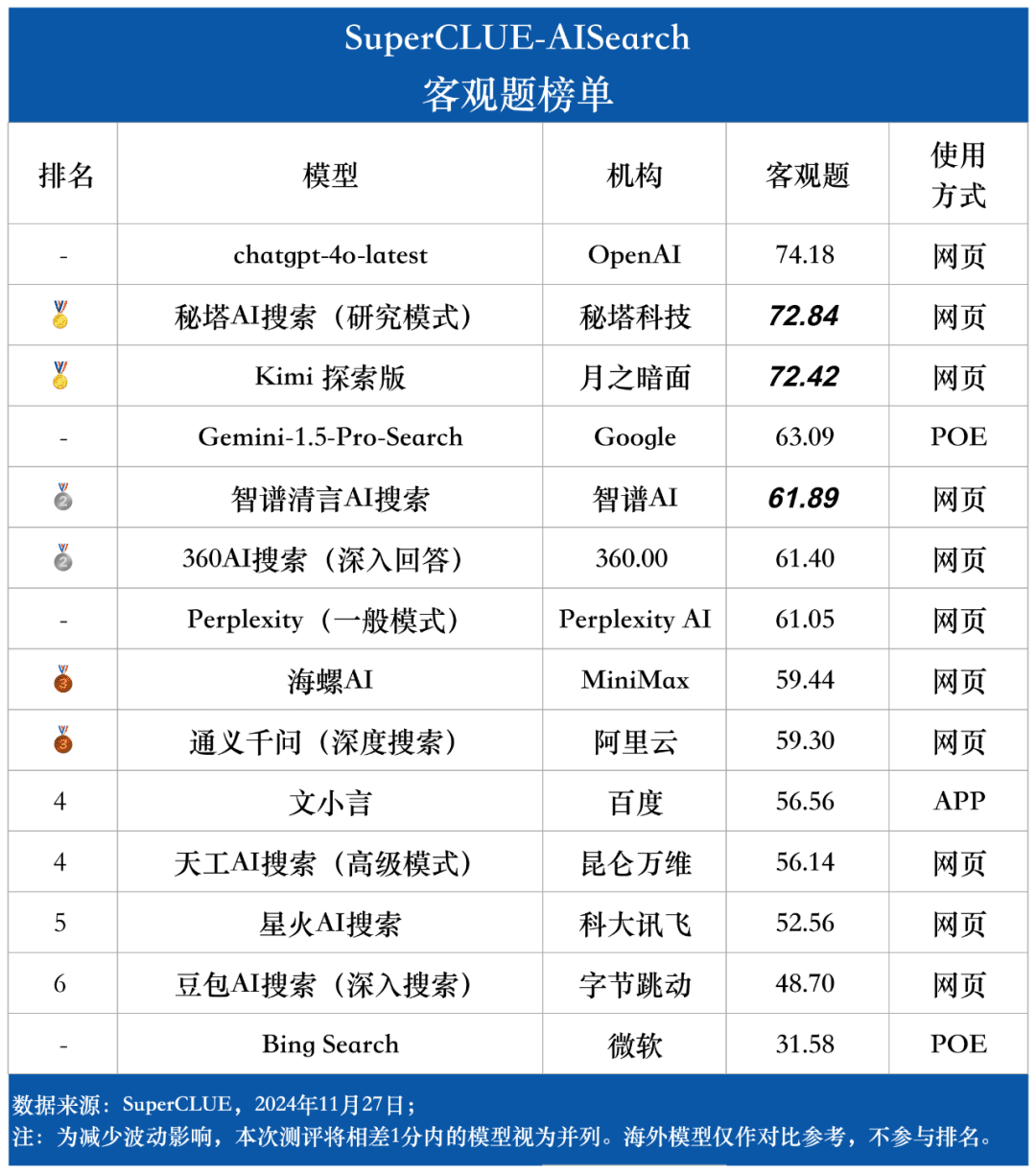
模型对比示例
示例1 基础能力-推理分析能力
提示词Prompt:「GPT-1 模型的结构为什么用 Transformer 而不是 LSTM?」
模型回答比较(满分5分):
【Kimi探索版】:4分 
【chatgpt-4o-latest】:3.9分 
【天工AI搜索(高级模式)】:3.4分 
示例2 基础能力-跨领域关联
提示词Prompt:「请你帮我找计算机视觉技术在农业中的3项应用,并简单介绍一下。」
模型回答比较(满分5分):
【秘塔AI搜索(研究模式)】:4分 
【文小言】:3.4分 
【星火AI搜索】:3分 
示例3 场景应用-股票
提示词Prompt:「请告诉我近年来A股中的几次重要牛市及其相关数据(如起始时间、持续时间、涨幅、最高和最低点等)。」模型回答比较(满分5分):【Gemini-1.5-Pro-Search】:3.2分 
【智谱清言AI搜索】:3.3分
【Bing Search】:2.6分
示例4 场景应用-生活
提示词Prompt:「今年1至10月,我国汽车产销量分别达到了多少万辆,并且与去年同期相比增长了多少百分比?」
模型回答比较(满分5分):
【通义千问(深度搜索)】:4.2分
【360AI搜索(深入回答)】:3.8分
人类一致性评估
为确保大模型自动化测评的科学性,我们对GPT-4o-0513在AI搜索评价任务中的人类一致性进行了评估。
具体操作方法为:选取5个模型,并由每个模型分配一个人进行独立打分,分别针对主客观题的不同维度进行评分,然后按照评分标准加权求平均。我们计算每道题目人类评分与模型评分的差值,求和取平均后得到每道题的平均差距作为人类一致性评估结果。
最终得到的平均结果为(百分制):5.1分
此次自动化评估具有较高的可靠性。
测评分析及结论
1. AI搜索综合能力,chatgpt-4o-latest保持领先。
从测评结果来看,chatgpt-4o-latest(73.41分)在综合能力上表现出色,领先SuperCLUE-AISearch基准模型。与国内最优秀的Kimi探索版相比,仅高出0.71分。
2. 国内大模型表现亮眼,各模型间差异较小
测评结果显示,秘塔AI搜索(研究模式)、智谱清言AI搜索和海螺AI等国内模型在基础能力上表现良好,呈现出追赶海外大模型Gemini-1.5-Pro-Search的态势。总体而言,综合成绩中游的国内多款模型如海螺AI、文小言及通义千问(深度搜索)间的表现相近,展现出较小偏差。
3. 不同场景应用中,模型展现出不同程度的表现。
在AI搜索的考察中,我们重点分析了模型在不同场景应用下的表现情况。国内大模型在科技、文化、商业和娱乐领域表现较为优异,能够准确把握信息的时效性,并展现出较强的信息检索与整合能力。然而,在股票、体育等场景应用中,国内大模型仍存在提升空间。
例如,在AI搜索过程中,模型需要准确解析用户的搜索需求,准确搜索相关网页以及及时提供信息,最终整合这些信息形成有实用性的回答。当前观察表明,国内大模型在某些情况下未能准确识别搜索需求,整合信息时有时参考了不相关的网页内容,导致其在特定场景应用中的表现不尽如人意。




暂无评论