
(adsbygoogle=window.adsbygoogle||[]).push({});
自从 Chatgpt 于2018年问世以来,各大企业在LLM(大语言模型)的参数量竞争上不断升级。GPT-1的参数量为1.17亿(117M),而其第四代GPT-4的参数量则已达到1.8万亿(1800B)。
其他LLM模型如Bloom(1760亿,176B)和Chinchilla(700亿,70B)的参数量同样呈现上升趋势。参数数量直接影响模型的性能,更多的参数使模型能够处理更复杂的语言模式,理解更丰富的上下文信息,并在多项任务中展示出更高的智能水平。
然而,这些巨大的参数量不仅提升了LLM的性能,也显著增加了训练成本,限制了许多普通研究机构对LLM的探索,使得大语言模型逐渐演变为大型企业之间的军备竞赛。
近期,新兴AI公司TensorOpera推出了开源的小型语言模型FOX,证明小语言模型(SLM)在智能体领域同样具备优越的实力。

FOX是一个专为云计算和边缘计算设计的小型语言模型。与参数数量动辄上百亿的大语言模型相比,FOX仅具备16亿参数,却在多项任务中展现出卓越的表现。
论文题目:
FOX-1 TECHNICAL REPORT
论文链接:
https://arxiv.org/abs/2411.05281

TensorOpera 介绍
TensorOpera是一家位于加州硅谷的创新AI公司,曾推出TensorOpera® AI Platform生成型AI生态系统以及TensorOpera® FedML联邦学习与分析平台。公司名称“TensorOpera”融合了技术与艺术,象征着GenAI推动多模态和多模型复合AI系统发展的方向。

TensorOpera的联合创始人兼CEO Jared Kaplan博士表示:“FOX模型的设计初衷在于在保证高性能的同时,显著降低计算资源的需求。这不仅使AI技术更加亲民,也为企业降低了使用门槛。”
FOX模型的设计思路
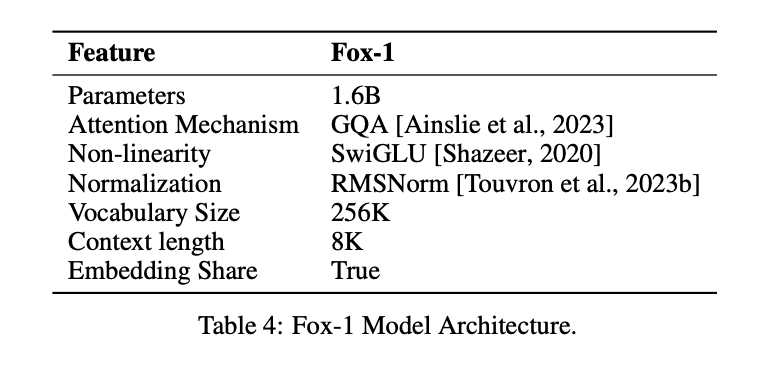
FOX-1模型仅采用解码器架构,通过多项改进和重新设计,达到了与LLM相似的性能。 具体包括:
① 网络层数:在设计模型架构时,更宽且更浅的神经网络具有更好的记忆能力,而更深更瘦的网络则具有更强的推理能力。依据这一原则,FOX-1的架构比大多数现代SLM更深,具体由32个自注意力层组成,深度比Gemma-2B(18层)多出78%,比StableLM-2-1.6B(24层)和Qwen1.5-1.8B(24层)多出33%。
② 共享嵌入:FOX-1采用2048的隐藏维度构建256,000的词汇表,所需数据量约5亿参数。通常情况下,更大的模型在输入层和输出层分别使用独立的嵌入层。为降低参数总量,FOX-1将输入和输出的嵌入层进行共享,从而提高权重的利用率。
③ 预归一化:FOX-1使用RMSNorm对每个变换层的输入进行归一化。在当前的大型语言模型中,RMSNorm被认为是预归一化的优选,表现出更高的效率。
④ 旋转式位置编码(RoPE):FOX-1默认支持最多8K长度的input token。为提升对长上下文窗口的处理能力,FOX-1采用旋转式位置编码,其中θ设置为10,000,以增强token之间的相对位置依赖性。
⑤ 分组查询注意力(GQA):分组查询注意力将多头注意力层的查询头分组,每组共享同一组键值头。FOX-1配备4个键值头和16个注意力头,以提升训练及推理速度,降低内存使用。
除模型结构的改进外,FOX-1在分词(Tokenization)和训练方法上也进行了优化。
分词优化:FOX-1采用基于SentencePiece的Gemma分词器,提供256K的词汇表大小。增大词汇表的主要优势包括:首先,因每个token编码的信息更密集,上下文隐藏信息的长度得以延长;其次,更大的词汇表降低了未知单词或短语的概率,从而在实际运用中提升了下游任务的性能。FOX-1所用的大词汇表对于给定文本语料库,产生的token数量较少,从而增强了推理性能。
FOX-1的预训练数据来自Redpajama、SlimPajama、Dolma、Pile及Falcon数据集,共计3万亿个文本数据。为提高注意力机制在长序列训练中的效率,FOX-1在预训练阶段引入了三阶段课程学习策略,通过将训练样本的chunk长度从2K逐步增加到8K,低成本地提升长上下文的能力。为了与三阶段课程预训练保持一致,FOX-1将原始数据重新整理为三个不同数据集,涵盖无监督数据、指令调优数据,以及代码、互联网内容、数学和科学文档等多个领域的数据。
FOX-1的训练可分为三个阶段:
- 第一阶段包含约39%总数据样本,使用1.05万亿token,样本长度为2,000,batch size设置为2M。在这一阶段使用了2,000个epoch进行线性预热。
- 第二阶段包括约59%样本,共1.58万亿token,并将chunk长度从2K增加到4K和8K。实际chunk长度根据不同数据源进行调整,考虑到第二阶段时间最长且来源多样,batch size提升至4M以提高训练效率。
- 最后在第三阶段,FOX模型使用62亿token(约总量的0.02%)的高质量数据进行训练,奠定了其在指令遵循、闲聊和特定领域问答等多项下游任务中的能力基础。
FOX-1的表现
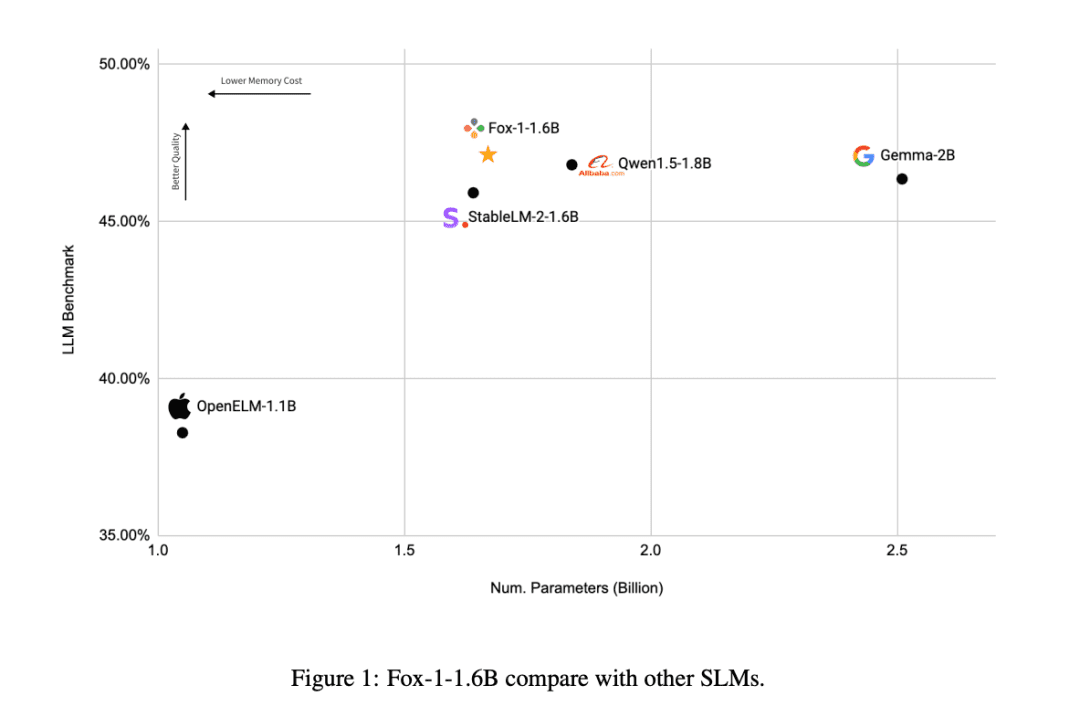
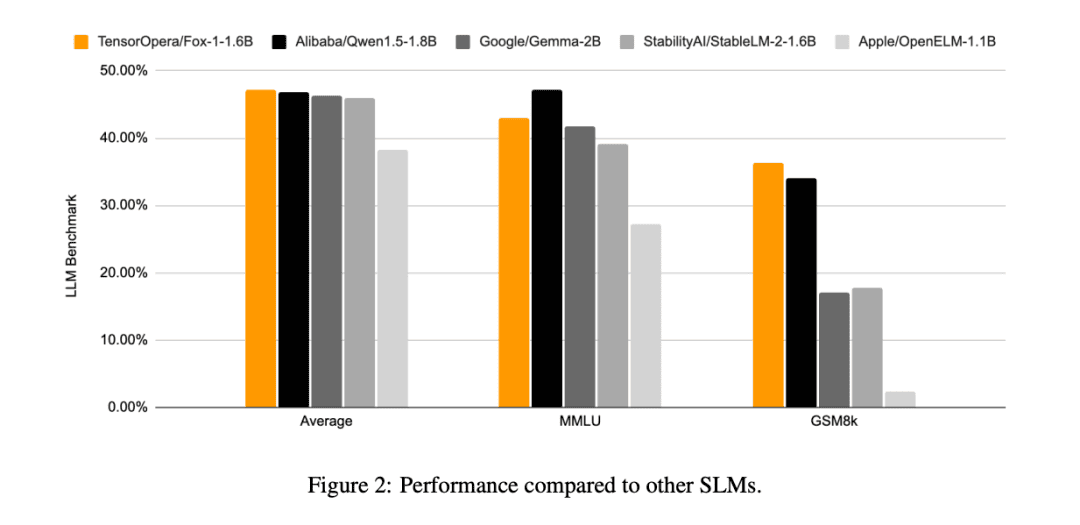
与其他SLM模型(Gemma-2B,Qwen1.5-1.8B,StableLM-2-1.6B和OpenELM1.1B)相比,FOX-1在ARC挑战(25-shot)、HellaSwag(10-shot)、TruthfulQA(0-shot)、MMLU(5-shot)、Winogrande(5-shot)和GSM8k(5-shot)六项任务的基准测试中平均得分最高,且在GSM8k上的表现尤为突出。
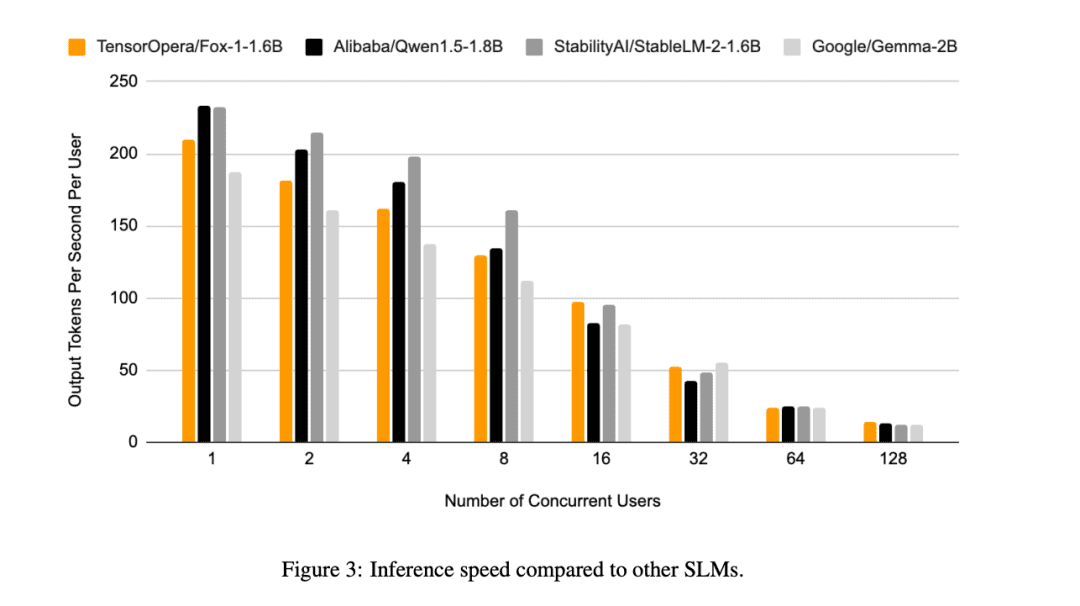
此外,TensorOpera还评估了FOX-1、Qwen1.5-1.8B和Gemma-2B在单个NVIDIA H100上的端到端推理效率,使用vLLM与TensorOpera服务平台进行对比。
FOX-1实现了每秒超过200个token的吞吐量,超越了Gemma-2B,并与Qwen1.5-1.8B在相同部署环境中的表现持平。在BF16精度下,FOX-1仅需3703MiB GPU内存,而Qwen1.5-1.8B、StableLM-2-1.6B和Gemma-2B分别需要4739MiB、3852MiB和5379MiB。
小参数,强竞争力
在各家AI公司围绕大语言模型展开竞争的背景下,TensorOpera另辟蹊径,在SLM领域取得突破,仅用1.6B参数实现了与LLM相似的效果,在各项基准测试中表现优异。
即使在数据资源有限的情况下,TensorOpera依旧成功预训练出具有竞争力的语言模型,为其他AI公司的研发提供了全新的思路。






暂无评论