大型语言模型(LLM)虽然能力日益增强,但“幻觉”现象——即模型生成内容中出现的与原文无关或错误信息——依然是限制其广泛应用和深度信任的关键问题。为量化评估此问题,Hughes Hallucination Evaluation Model (HHEM) 排行榜应运而生,专注于评估主流 LLM 在生成文档摘要时的幻觉频率。
“幻觉”是指模型在摘要中添加了原始文档未包含甚至相反的“事实”。对于依赖 LLM 进行信息处理的场景,尤其是基于检索增强生成(RAG)的应用,这是一个关键的质量瓶颈。如果模型无法忠实于输入信息,其输出的可信度将大打折扣。
(adsbygoogle=window.adsbygoogle||[]).push({});
HHEM 如何工作?
HHEM 排行榜使用 Vectara 公司开发的 HHEM-2.1 幻觉评估模型。该模型会对源文档和特定 LLM 生成的摘要进行对比,输出一个介于 0 到 1 之间的幻觉分数。分数越接近 1,表示摘要与源文档的事实一致性越高;越接近 0,则表示幻觉越严重,甚至完全是虚构内容。Vectara 还提供了一个开源版本 HHEM-2.1-Open,供研究人员和开发者本地评估,其模型卡发布在 Hugging Face 平台。
评估基准
评估使用了包含 1006 份文档的数据集,主要来源于公开数据集,如 CNN/Daily Mail Corpus。项目团队使用参与评估的各个 LLM 为每份文档生成摘要,然后计算每对(源文档,生成摘要)的 HHEM 分数。为标准化评估,所有模型调用均设置 temperature 参数为 0,以获取模型最具确定性的输出。
评估指标包括:
- 幻觉率 (Hallucination Rate): HHEM 分数低于 0.5 的摘要所占的百分比。此值越低越好。
- 事实一致性率 (Factual Consistency Rate): 100% 减去幻觉率,反映了摘要内容忠实于原文的比例。
- 回答率 (Answer Rate): 模型成功生成非空摘要的百分比。部分模型可能因内容安全策略或其他原因拒绝回答或出错。
- 平均摘要长度 (Average Summary Length): 生成摘要的平均词数,可反映模型的输出风格。
LLM 幻觉排行榜解读
以下是基于 HHEM-2.1 模型评估得出的 LLM 幻觉排行榜(数据截至 2025 年 3 月 25 日,请以实际更新为准):
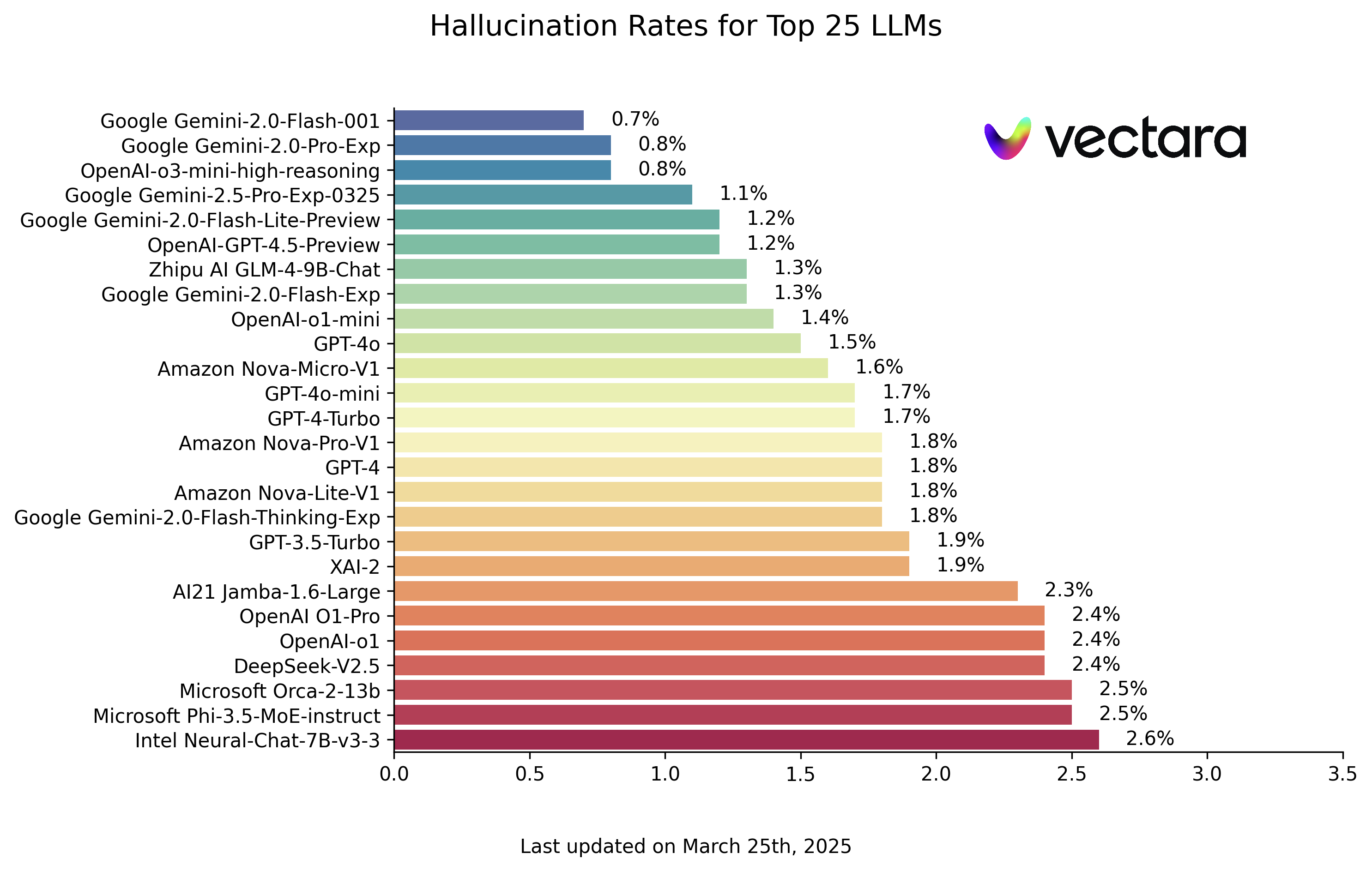
| Model | Hallucination Rate | Factual Consistency Rate | Answer Rate | Average Summary Length (Words) |
|---|---|---|---|---|
| Google Gemini-2.0-Flash-001 | 0.7 % | 99
相关推荐
Anthropic宪法分类器防御AI越狱Anthropic发布规则分类器,防御大语言模型越狱攻击。 
AI赋能游戏创新:深度解析Steam平台AI-Native游戏AI驱动游戏创新,融合AI技术提升互动性和沉浸感。 
AI工具化新纪元:MCP协议与智能体生态重构AI智能体交互生态革新,MCP协议赋能工具集成 
AI图像生成技术革新:ChatGPT集成GPT-4o,开启无限创意新纪元OpenAI将图像生成技术整合进ChatGPT,推出不限量使用DeepSeek-R1和Doubao-pro,提升便捷性,加速AI图像生成普及。 |

暂无评论