在当前科技迅猛发展的背景下,人工智能技术已深入到我们日常生活的各个角落。从智能语音助手到自动化服务,AI正以前所未有的方式改变我们的生活。今天,我要向大家介绍一项极具创意的技术——Spark-TTS,这是一款基于Qwen2.5模型的高效文本转语音系统。它不仅能复制你的声音,还能根据你的需求定制全新的声音,听起来是不是很神奇?
### 什么是Spark-TTS?
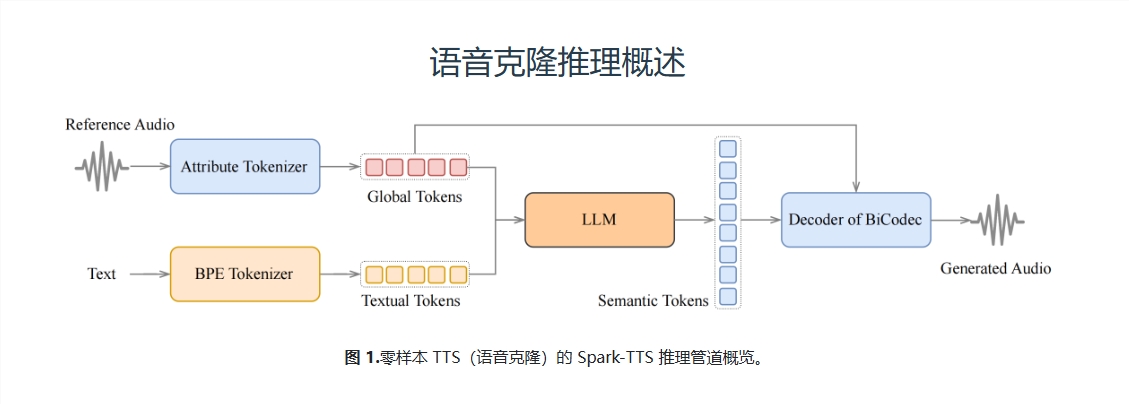
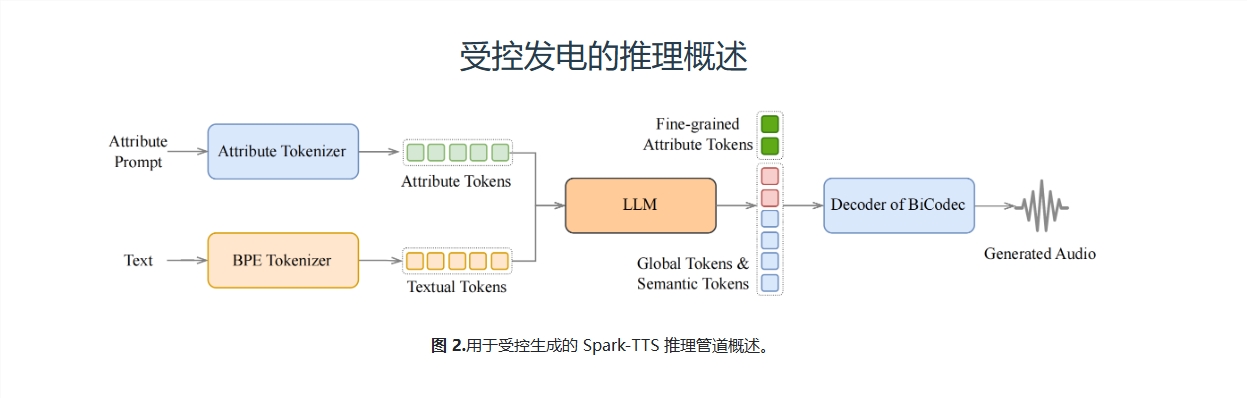
Spark-TTS是一款创新的文本转语音(TTS)系统,其核心是BiCodec——一种单流语音编解码器。这种编解码器能将语音分解为两种互补的“语音令牌”:一种是低比特率的语义令牌,用于捕捉语言内容;另一种是固定长度的全局令牌,用于捕捉说话者的属性,如音色、音调等。这种分离式的表示方法,结合了强大的Qwen2.5语言模型和“思维链”(CoT)生成方法,使Spark-TTS能够从粗粒度(如性别、说话风格)到细粒度(如精确的音高值、说话速度)进行控制。换句话说,你只需简单指令,Spark-TTS就能生成一个符合你想象的声音!
### Spark-TTS的“超能力”
Spark-TTS的强大之处在于其“超能力”——实现零样本的声音克隆。这意味着,你只需提供一段参考音频,Spark-TTS就能直接生成一个全新的声音,并完全按照你的要求进行调整。例如,你可以要求生成一个“男性、低音、慢速”的声音,Spark-TTS就能精准地完成任务。这在以前几乎是不可能实现的,但Spark-TTS做到了!
此外,Spark-TTS还有一个“秘密武器”——VoxBox。这是一个包含10万小时语音数据的开源数据集,涵盖了各种属性的标注,如性别、音高和说话速度。这个数据集为语音合成研究提供了一个标准化的基准,帮助研究人员更好地进行实验和比较。
### 技术细节
Spark-TTS的技术细节可能听起来有些复杂,但我会用最通俗易懂的方式解释。首先,BiCodec是Spark-TTS的核心,它通过“矢量量化”(VQ)技术将语音信号转换成离散的令牌。这些令牌就像是语音的“数字指纹”,可以被语言模型理解和生成。然后,Spark-TTS利用Qwen2.5语言模型的强大能力,通过“思维链”生成方法,将这些令牌组合成完整的语音信号。
在实际应用中,Spark-TTS有两种工作模式:零样本模式和可控生成模式。在零样本模式下,Spark-TTS可以根据参考音频生成一个全新的声音;而在可控生成模式下,你可以通过指定属性标签或具体数值,让Spark-TTS生成完全符合你要求的声音。例如,你可以要求生成一个“女性、高音、快速”的声音,Spark-TTS就能精准地完成任务。
### 实际应用
Spark-TTS的应用场景非常广泛。例如,在智能语音助手领域,Spark-TTS可以根据用户的偏好生成个性化的语音,让用户感觉像是在和一个真正的人交流。在有声读物领域,Spark-TTS可以根据文本内容生成不同风格的声音,为听众带来更丰富的听觉体验。此外,Spark-TTS还可以用于语音合成研究,帮助研究人员更好地理解和改进语音合成技术。
### 未来展望
尽管Spark-TTS已经取得了很大的突破,但仍有一些需要改进的地方。例如,在零样本声音克隆中,Spark-TTS的说话者相似度还有待提高。此外,Spark-TTS目前还没有对全局令牌和语义令牌之间的解耦进行额外的约束,这可能会影响声音的多样性和自然度。不过,研究人员已经在探索新的方法来解决这些问题,例如通过引入音色的扰动来提高声音的多样性和自然度。
Spark-TTS是一项非常有前景的技术,它不仅能够实现零样本的声音克隆,还能根据用户的需求生成全新的声音。它的出现,让我们看到了语音合成技术的无限可能。未来,随着技术的不断进步,Spark-TTS有望在更多领域得到应用,为我们的生活带来更多便利和乐趣。
最后,如果你对Spark-TTS感兴趣,可以访问它的开源代码和音频样本,亲自感受一下这项神奇的技术。相信我,这将是一次非常有趣的体验!
项目及演示:[https://sparkaudio.github.io/spark-tts/](https://sparkaudio.github.io/spark-tts/)
GitHub:[https://github.com/SparkAudio/Spark-TTS](https://github.com/SparkAudio/Spark-TTS)
论文:[https://arxiv.org/pdf/2503.01710](https://arxiv.org/pdf/2503.01710)





暂无评论