阿里云宣布其通义千问项目开源了最新的视觉模型Qwen2.5-VL,并提供了3B、7B和72B三个不同规模的版本。
在13项权威评测中,Qwen2.5-VL-72B版在视觉理解领域取得了领先,超越了GPT-4o和Claude3.5。阿里云官方指出,新模型能更精确地分析图像,并具备解析超过一小时视频内容的能力。它能帮助用户在视频中查找特定事件,对视频的不同阶段进行要点总结,迅速提取关键信息。
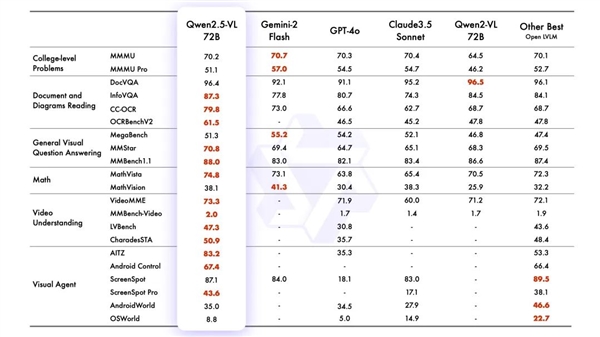
Qwen2.5-VL无需微调即可成为具备操控手机和电脑能力的AI视觉智能体,能够执行如发送祝福、电脑图像编辑、手机订票等复杂操作。此模型不仅擅长识别花卉、鸟类、鱼类和昆虫等常见物体,还能分析图像中的文本、图表、图标、图形和布局。阿里云还提升了Qwen2.5-VL的OCR识别能力,增强了其在多场景、多语言和多方向上的文本识别和定位功能。

此外,Qwen2.5-VL在信息抽取能力上也有了显著提升,以满足资质审核、金融商务等数字化和智能化领域的日益增长需求。
划重点:
🌟 阿里云通义千问开源Qwen2.5-VL,提供3B、7B和72B三个版本。
📈 Qwen2.5-VL-72B在视觉理解评测中领先于GPT-4o与Claude3.5。
👀 Qwen2.5-VL支持超1小时视频理解,OCR识别能力增强。




暂无评论