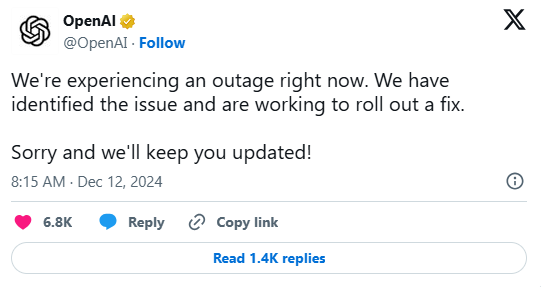
12月11日上周,OpenAI的ChatGPT和Sora等服务遭遇了长达4小时10分钟的停机事件,影响了许多用户。目前,OpenAI已正式公布了ChatGPT停机故障的详细报告。

简而言之,此次故障源于一个微小的变更,却引发了严重后果。在关键时刻,工程师们被阻挡在控制面板之外,无法及时解决问题。针对这一故障,OpenAI的工程师们在发现问题后迅速实施了多项修复措施,包括缩减集群规模、阻止对Kubernetes管理API的网络访问以及为Kubernetes API服务器增加资源。经过连续几轮努力,工程师们终于恢复了对部分Kubernetes控制面板的访问,并采取措施将流量引导至健康集群,实现了系统的全面恢复。
事故发生在太平洋标准时间下午3点12分,当时工程师们为了收集Kubernetes(K8S)控制面板指标,部署了一项新的遥测服务。然而,由于配置失误,该服务在所有集群的每个节点上同时执行了资源密集型的K8S API操作,导致API服务器迅速崩溃,大部分集群的K8S数据面板因此失去服务能力。
值得注意的是,尽管K8S数据面板在理论上可以独立于控制面板运行,但DNS功能依赖于控制面板,导致服务间无法正常通信。当API操作过载时,服务发现机制受损,引发了整个服务的瘫痪。虽然问题在3分钟内被定位,但由于工程师无法访问控制面板进行服务回滚,导致了“死循环”的局面。控制面板的崩溃使他们无法删除有问题的服务,从而无法恢复系统。
OpenAI的工程师们立即开始尝试不同的方法来恢复集群。他们尝试缩小集群规模以减轻K8S API的负载,并阻止对管理K8S API的访问,以便服务器能够恢复正常运行。同时,他们还增加了K8S API服务器的资源配置,以更好地处理请求。经过一系列努力,工程师们终于重新控制了K8S控制面板,成功删除了故障服务并逐步恢复了集群。
在此过程中,工程师们还将流量转移至已恢复或新增的健康集群,以减轻其他集群的负担。然而,由于众多服务同时尝试恢复,导致资源限制饱和,恢复过程需要额外的手动干预,部分集群的恢复时间较长。通过此次事件,OpenAI有望吸取教训,防止未来再次出现类似的“锁门”情况。
报告详情: https://status.openai.com/incidents/ctrsv3lwd797
划重点:
🔧 故障原因:一项小的遥测服务变更导致K8S API操作过载,引发服务瘫痪。
🚪 工程师困境:控制面板崩溃,工程师无法访问,导致问题无法处理。
⏳ 恢复过程:通过缩减集群规模和增加资源等措施,最终恢复了服务。


暂无评论