谷歌的人工智能研究部门近日推出了Gemini AI模型的升级版——Gemini2.0Flash。这一新模型在性能上实现了显著飞跃,尤其是在处理速度和多模态功能扩展方面。
官方透露,全球的Gemini用户现在可以在桌面和移动Web的模型下拉菜单中选择2.0Flash实验版,以体验优化的聊天功能,而且该版本很快也将登陆Gemini移动应用。预计明年年初,Gemini2.0将扩展至更多谷歌产品。

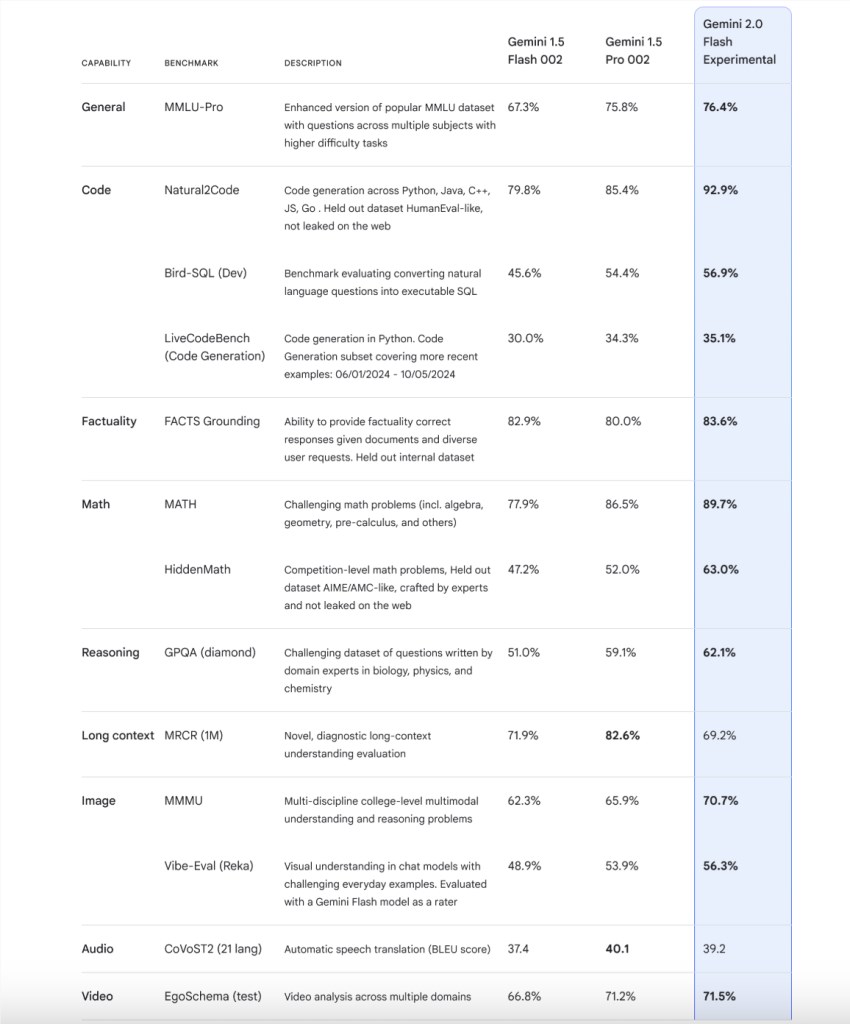
Gemini2.0Flash的核心亮点是其处理速度的大幅提升。谷歌宣称,新模型的运行速度是前一代Gemini1.5Pro的两倍,同时在多项基准测试中也展现了更优异的性能。这一速度提升意味着用户将享受到更高效的处理能力和更快的响应。
此外,Gemini2.0Flash在处理多种数据类型方面也有所增强。模型新增了一个多模态实时API,能够实时处理音频和视频流,使开发者能够创建利用动态音频和视觉输入的应用。同时,模型还整合了原生图像生成功能,允许用户通过对话式文本提示来创建和编辑图像。
除了这些主要进步,Gemini2.0Flash还加入了多项增强功能。现在支持八种不同的声音,实现了原生多语言音频输出,进一步扩大了模型的全球适用性。对工具和代理的支持也得到了改进,使模型能够更有效地与外部工具和系统互动,完成更复杂的任务。
在软件工程任务方面,Gemini2.0Flash在SWE-bench Verified基准测试中取得了51.8%的得分,这一测试旨在评估编码能力。这一成绩展示了模型在辅助开发者进行代码编写、调试和优化方面的潜力。
谷歌正在将Gemini2.0Flash整合进自家的开发工具。一个新的AI驱动代码代理Jules已经在Google Colaboratory中利用Gemini2.0Flash为开发者提供帮助,展示了模型在实际开发环境中的应用。
Gemini2.0Flash还包含了与负责任的AI开发相关的特性。支持109种语言,进一步扩大了模型的全球适用性。所有生成的图像和音频都嵌入了SynthID水印,为追踪来源和解决与AI生成内容相关的潜在问题提供了机制。
Gemini2.0Flash的发布标志着谷歌AI模型发展的又一里程碑。它专注于提升速度、扩展多模态能力以及改善工具交互,为打造更通用、更强大的AI系统做出了贡献。
随着谷歌继续推进Gemini系列模型的开发,预计将带来更精细的优化和能力拓展。Gemini2.0Flash为AI技术的持续发展及其在各领域的潜在应用奠定了基础。
官方介绍:https://blog.google/technology/google-deepmind/google-gemini-ai-update-december-2024/
划重点:
🚀 Gemini2.0Flash的速度是前代的两倍,性能显著提升。
🎥️ 模型新增多模态实时API,支持音频和视频流的实时处理。
🌐️ 原生图像生成功能集成,通过文本提示创建和修改图像。





暂无评论