Google 推出 Gemini 2.0 Flash 新系列模型,包括 Gemini 2.0 Flash、Flash-Lite 和 Pro,旨在为开发者提供更高效、经济、强大的 AI 解决方案。其中,Gemini 2.0 Flash 现已全面可用,具备更高的速率限制和强大性能;Flash-Lite 提供成本效益;而 Pro 版本针对编码和复杂任务优化。所有模型均支持百万 Token 上下文窗口,并提供原生工具使用和多模态输入等高级功能,助力开发者构建更强大的 AI 应用。同时,定价大幅降低,并附赠便捷的开发工具和免费层级,方便开发者快速扩展应用规模。

**Gemini 2.0 系列为开发者提供更多选择**
Google 今天发布了激动人心的更新,旨在让更多开发者使用并投入生产。以下模型现已通过 Google AI Studio 和 Vertex AI 在 Gemini API 中提供:
- Gemini 2.0 Flash 全面上市,具备更高速率限制、更强性能和简化定价。
- Gemini 2.0 Flash-Lite 作为新变体,是 Google 迄今最具成本效益的模型,现已公开发布预览版。
- Gemini 2.0 Pro 是 Google 迄今用于编码和复杂提示的最佳模型的实验性更新,现已发布。
除了最近发布的 Gemini 2.0 Flash Thinking Experimental,这些新版本使得 Gemini 2.0 的功能能够应用于更广泛的用例和应用场景。
**模型特性**
Gemini 2.0 Flash 提供全面特性,包括原生工具使用、100 万 Token 上下文窗口和多模态输入。目前支持文本输出,图像和音频输出功能以及多模态 Live API 计划在未来几个月内全面推出。Gemini 2.0 Flash-Lite 经过成本优化,适用于大规模文本输出用例。

**模型性能**
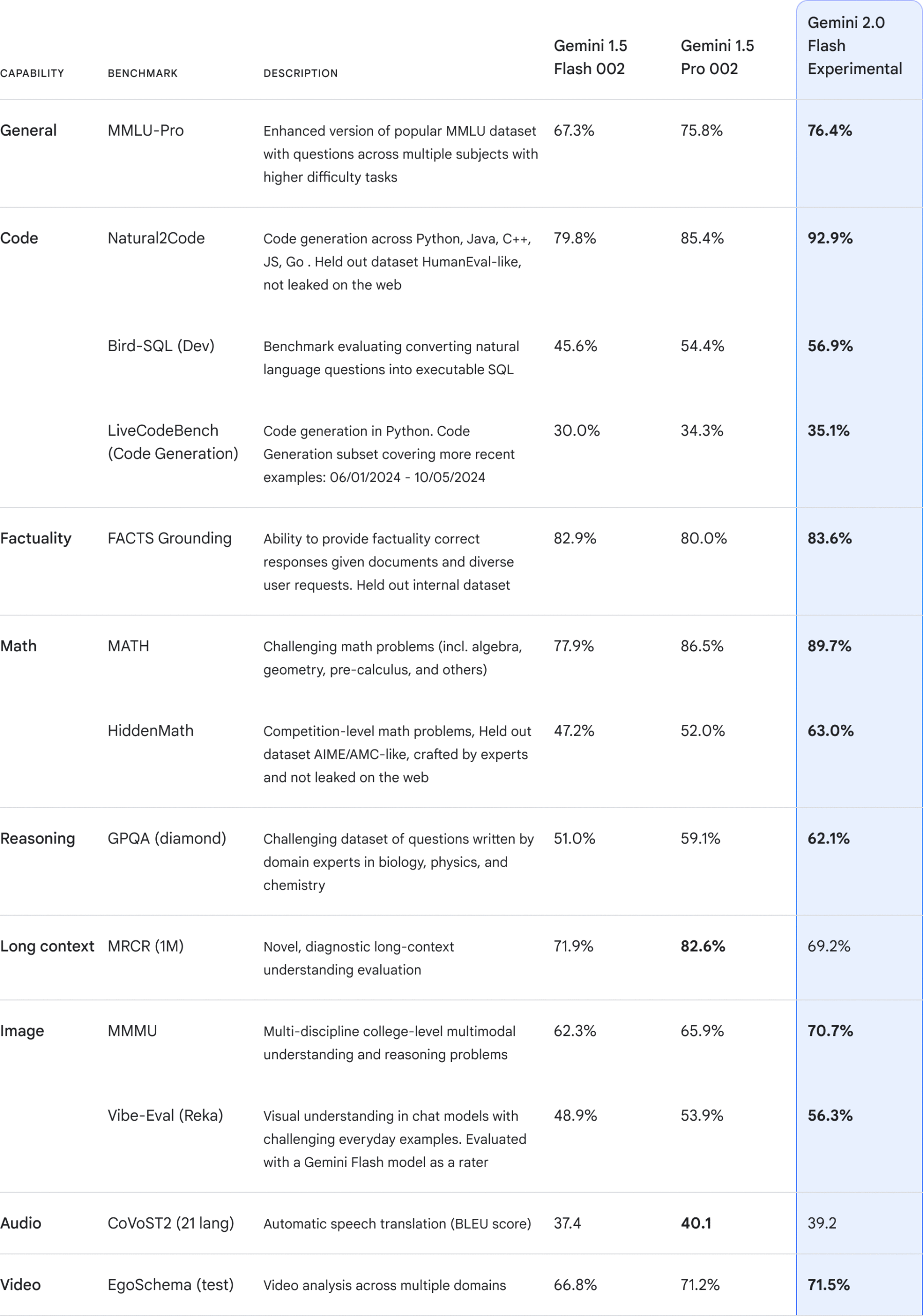
Gemini 2.0 模型在各种基准测试中,相较于 Gemini 1.5 实现了显著性能提升。

与之前的模型类似,Gemini 2.0 Flash 默认采用简洁风格,使其更易于使用并降低成本。此外,它还可以通过提示使用更详尽的风格,在面向聊天的用例中获得更出色的结果。
**Gemini 定价**
Google 通过 Gemini 2.0 Flash 和 2.0 Flash-Lite 降低成本。这两款模型都对每种输入类型采用单一价格,取消了 Gemini 1.5 Flash 在短上下文请求和长上下文请求之间所做的区分。这意味着,尽管 2.0 Flash 和 Flash-Lite 都带来了性能提升,但在混合上下文工作负载下,它们的成本可能比 Gemini 1.5 Flash 更低。

注:对于 Gemini 模型,一个 tonkes 大约相当于 4 个字符。100 个词元大约相当于 60-80 个英语单词。





暂无评论