推理本身是不可预测的,因此我们必须从令人难以置信且不可预测的 AI 系统入手。
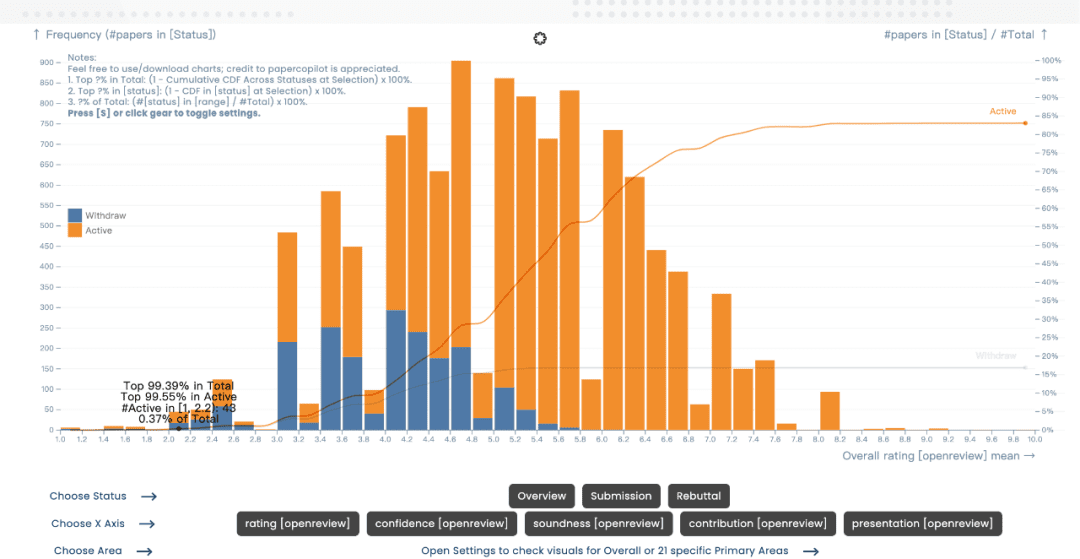
Ilya 终于现身了,而且一开口便提出了震撼的观点。本周五,OpenAI 的前首席科学家 Ilya Sutskever 在全球 AI 顶会上表示:“我们能获取的数据已经到达瓶颈,不会再有更多了。” 
Ilya Sutskever 今年 5 月离开 OpenAI,创办了自己的人工智能实验室 Safe Superintelligence,成为了新闻焦点。自离开 OpenAI 之后,他便鲜少露面,但本周五,他在温哥华举行的神经信息处理系统会议 NeurIPS 2024 上公开亮相。
(adsbygoogle=window.adsbygoogle||[]).push({});
他说:“我们熟知的预训练模式无疑会走到尽头。”
在人工智能领域,BERT、GPT 等大规模预训练模型(Pre-Training Model)近几年取得了显著的进展,成为技术发展史上的里程碑。
由于复杂的预训练目标和庞大的模型参数,大规模预训练能够高效地从大量标记和未标记的数据中提取知识。通过将知识储存在庞大的参数中,并在特定任务上进行微调,这些参数中隐式编码的丰富知识可使各类下游任务受益。如今,AI 社区普遍认为,预训练已成为下游任务的基础,而非从零开始训练模型。 
然而,在 NeurIPS 演讲中,Ilya Sutskever 表示,尽管当前的数据依然能够推动人工智能的发展,但称得上新颖且可用的数据已经几乎枯竭。他指出,这一趋势最终将迫使行业改变现有的模型训练方式。
Sutskever 将这一情况比作化石燃料的消耗,指出就像石油是有限的,互联网中由人类生成的内容也是有限的。
他说:“我们已经达到数据的极限,未来不会再有更多的数据了。我们必须利用现有的数据,因为互联网只有一个。”
Sutskever 预言,下一代 AI 模型将会展现出“真正的自主性”。与此同时,智能体(Agent)已经成为 AI 领域的热词。
除了自主性,他还提到未来的 AI 系统将具备推理能力。与现今 AI 系统主要依赖模式匹配(基于模型先前见过的内容)不同,未来的 AI 将能够以类似“思考”的方式逐步解决问题。
Sutskever 还表示,系统的推理能力越强,其行为就越“不可预测”。他将“真正具备推理能力的系统”的不可预测性与高级 AI 在国际象棋中的表现进行了类比:“即便是最顶尖的人类棋手也无法预测它们的动作。”
他说:“这些系统将能从有限的数据中理解事物,并且不会感到困惑。”
在演讲中,他将 AI 系统的 Scaling 与进化生物学进行了比较,并引用了不同物种之间大脑与体重比例关系的研究。他指出,大多数哺乳动物遵循某种特定的 Scaling 模式,而人类科(人类祖先)的脑体比在对数尺度上则表现出不同的增长趋势。
Sutskever 提议,就像进化过程中的人类科大脑找到了新的 Scaling 模式一样,AI 也可能超越现有的预训练方法,发现全新的扩展路径。以下是 Ilya Sutskever 演讲的完整内容: 
首先,我要感谢大会组织者为这项奖项选取了 Ilya Sutskever 等人的《Seq2Seq》论文,这篇论文荣获了 NeurIPS 2024 时间检验奖。我还要感谢我那不可思议的合著者 Oriol Vinyals 和 Quoc V. Le,他们刚刚站在你们面前。 

这是十年前在蒙特利尔的 NIPS 2014 上的一个类似演讲。那时是个更加纯真的时代。照片里的人也在这里。顺便说一下,那是上一次,而下面这张则是这一次。
现在我们有了更多的经验,也希望变得更加聪明。但是今天,我想谈谈这项工作本身,或许还做一个十年的回顾,因为这项工作中的许多观点今天看来仍然是正确的,尽管有些并不完全准确。我们可以回顾它们,看看我们走过的路,并且思考这一路如何带领我们走到了今天。
这是十年前的一张幻灯片,看起来不错,“深度学习假说”。我们当时说,如果你拥有一个有十层的大型神经网络,但它可以在几分之一秒内完成任何人类能够做的事情。

这是十年前的幻灯片,展示了深度学习假说。我们当时认为,假如你有一个十层的神经网络,它就能完成任何人类能够在短短几分之一秒内完成的任务。



暂无评论